一个简单的 Lock Free Ring Buffer,有多简单?
本文涉及到的代码见:https://github.com/LENSHOOD/go-lock-free-ring-buffer
Ring Buffer
Ring Buffer 是一种极其简单的数据结构,它具有如下常见的特性:
- 容量固定的有界队列,进出队列操作不需要整体移动队内数据
- 内存结构紧凑(避免 GC),读写效率高(常数时间的入队、出队、随机访问)
- 难以扩容
Lock Free Ring Buffer 系列文章:
Ideology
原理上 Ring Buffer 简单优雅:
1 | type ring struct { |
Reality
既然作为一种缓冲器,我们可以预见到 Ring Buffer 的一个主要场景就是在 Producer - Consumer 模式下均衡数据交换速率,削峰填谷。
因此天然的,我们期望一个 Ring Buffer 是 thread safe 的。
我们有很多种方式来避免入队和出队操作相互竞争,其中最简单的就是把共享变量:head、tail、element[]
用互斥锁保护起来。
但我们会发现,在前面代码中几乎每一条语句都涉及到共享变量的操作,所以我们只能用锁将整个函数体都包裹起来,导致临界区(Critical Section) 很大。
考虑到 Ring Buffer 超级简单,我们可以用 Lock Free 的方式来改造它吗?
- 虽然
element[]整体上是一个共享变量,但由于只有head和tail的持有者才能访问数据,所以不同的持有者访问element[]不同的 "slot",并不会发生竞争 tail只被 Producer 更新,head只被 Consumer 更新,head/tail之间不存在原子更新关系。tail和head都是单个整数类型变量,对其读写适用于CPU支持的原子操作(read-modify-write)
这么看来直接使用一些 atomic 操作,就能实现 lock-free 的 ring buffer 了!
Lock-Free Ring Buffer
前期准备
我们知道,在传统 SMP 架构下,确保多线程程序 memory ordering 的方式是采用 memory barrier + cache coherence protocol 来实现共享变量的访问在 cpu 不同核之间保持一致性与顺序性。
因此,我们需要根据共享变量(在本文的上下文中指的就是
tail/head/element[])的访问方式来确定其具体使用编程语言中的哪一种
memory order 抽象。
C++ 和 Java 都提供了较为细粒度的 memory order 抽象(c++
memory order、java
varhandle),但 go 提供的 atomic 包对 memory order
的控制比较粗略,因此我们能用得上的库函数只有如下几种:
1 | // 以下的 “XXX” 代表各种不同的类型如:uint32、int64、uintptr、unsafe.Pointer 等等 |
CAS 需要的 barrier 限制毋庸置疑,但对于
Load/Store,Go 在官方文档中只是讲这些提到这些函数能够
“atomically” 执行操作,但并没有说细节。不过从这里我们看到
rsc 在回复中提到说 Go 的 atomic 实现 ”能够保证 sequential
consistency,就像 c++ 的 seqconst“。那么我们就可以推断对共享变量进行
Load/Store操作就类似于在 java 中对
volatile 变量的操作行为。这也意味着最终我们的 lock-free
实现可能会相对较慢。
改造一下
原子化的 turn around
在改造为 lock-free 版本之前,我们发现了前述代码中的一个问题:
每当 head / tail 的值达到 capacity 后,我们需要将其重置为 0(即 turn
around 操作)。head/tail++ 与判断并重置为 0
是两个操作,无锁状态下它们无法同步。当然我们也可以先计算出新值,再用 CAS
来更新,但做得越多出错的概率越大,我们期望以更简单的方式来实现 ”turn
around“。
我们知道计算机补码的溢出性质:当一个无符号数向上溢出时,它变为
0。我们可以利用这一性质来限定
tail/head,但直接使用的问题是 capacity 只能是
2^8/16/32/64。
使用 Mask 就可以让 capacity 的选取变得更灵活:执行
head/tail & (2^n - 1) 就可以支持任意的二次幂
capacity。这样,我们对 capacity 的限制就只是要求二次幂了。
二次幂转换
我们不期望用户在创建 ring buffer 时需要了解到 ”capacity 必须是二次幂“ 这种细节问题,最简单的处理就是把用户输入的任意大于 0 的 capacity 值向上取值为其最近的二次幂。
如下代码能够即高效又简单的完成这一工作:
1 | func findPowerOfTwo(givenMum uint64) uint64 { |
替换 atomic 函数
经过前面的讨论,我们就可以初步的给出改造结果了:
1 | func (r *ring) Offer(v interface{}) bool { |
非同步下不可控的调度产生的问题
由于我们的代码中完全没有用到任何锁或同步块,因此单线程(或正确同步)下的一些代码假设就不再成立:
- 实时性:某两行代码,执行完第一行,下一行会立即执行
- Happens-before:第一行一定在第二行之前执行(只有添加了 memory barrier 的操作才会限制编译器、CPU 的重排序)
所以上一节的代码看似没问题,实际上是无法通过并发测试的(并发测试代码可以见这里),当我们拿多个线程一边生产一边消费时,很可能会出现如下两种异常情况:
- 重复消费:已经消费过的数据又一次被消费
- 覆盖生产:数据还没有被消费,就被新一次的生产所覆盖
上述两种异常都会导致生产的总数据与消费的总数据对不上,产生错误。本节会详细的讨论可能发生上述异常的三个场景,并给出了解决办法。
场景 1:CAS 与 Read/Write Value 不同步
最简单且可能发生的问题就是 head/tail
已经被更新,但值迟迟没有写入:
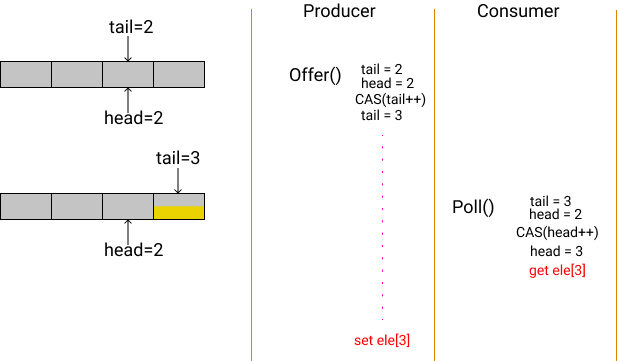
如上图所示,开始状态 buffer 为空,Consumer
因为空而停止消费。这时 Produer
开始送入数据,显然,图中Producer 的 CAS
操作已经成功,tail++已经发布给 Consumer
。意味着 Consumer已经被授权可以继续消费数据了。
但问题在于 Producer
并没有完成值的写入,而是被调度暂停。在这期间 Consumer
已经完成了数据的读取,那么显然读到了错误的数据。
要解决这样的问题,就在于需要在 element[] 的 slot 中告诉
Producer/Consumer
当前的值是否可用(已被发布/读取):
1 | func (r *ring) Offer(v interface{}) bool { |
Consumer 每次读取数据,都要判断是否为
nil,如果是则说明新值还有没写入;对应的,Producer
在写入之前也要判断值是否不为nil,如果是就说明还没有被消费完毕。
nil 值就像一道闸门,隔开了生产和消费的过程。
场景 2:Load Tail/Head 与 CAS 不同步(即 ABA)
ABA 问题算是 lock-free 中的经典问题了,讲的就是在 CAS 的时候,需要比较旧值和新值,但当值变化了数次之后,恰巧又变为与旧值相同的值时,CAS 是没法判断到底中间有没有变化的。
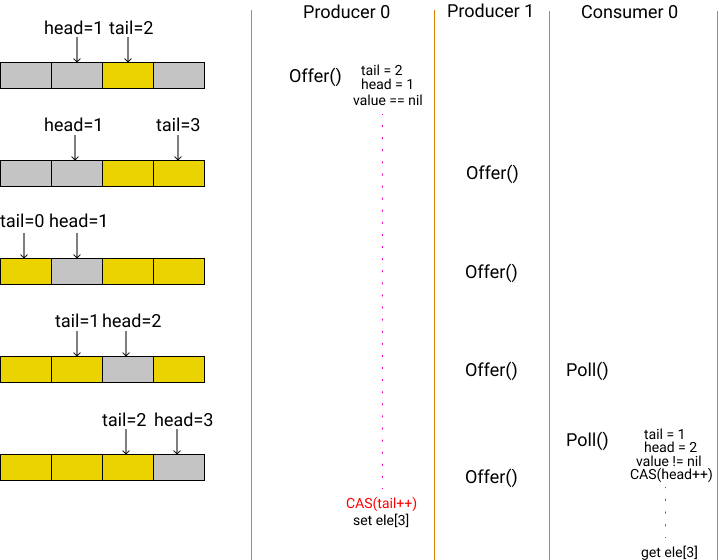
上面的图是说:Producer 0 顺利的通过了
isFull ,value == nil 的检查,准备
CAS,但这时被调度出让执行权,之后其他的 Producer 和
Consumer 欢快的执行了一整圈,然后 Producer 0
又拿到 CPU,开始执行 CAS。
按道理,过了这么久,CAS
必然会执行失败。但很悬的就是,tail 转了一圈,现在又恰巧和
Produer 0 先前读到的 oldTail 一样了,所以 CAS
顺利的执行完成,Producer 0
也愉快的写入了他本该在很早以前就写入的值。
但万万没想到的是,Producer 0
写入的数据,覆盖掉了原本存在,但没有被读取到的数据,因此
Consumer 0 在不知情的情况下读到了重复的数据。这就是典型的
ABA 问题。
怎么解决呢?
通常规避 ABA 问题就是引入版本号或者戳(stamp),这样在实现上让绕了一圈回到旧值的情况不可能或极难发生,就避免了 ABA:
1 | func (r *ring) Offer(value interface{}) (success bool) { |
和前文对比看,其实改动很小,原本计算 tail/head
是通过对其加一之后按位与 mask
来限制其值不会超限。现如今我们不限制head/tail
让它们可以无限制的加一,直到达到 uint64
的最大值后归零。
但在读写element[] 的时候对索引值进行按位与
mask,我们可以知道不论 head/tail
有多大,按位与 mask 之后的索引值一定不会超限导致
out of range。看起来似乎逻辑上和先前没差,但实际上由于
head/tail 的极限值被极大的增大了,现在再想要发生 ABA
问题,线程调度间隔之间要执行 2^64
次读/写,这几乎不可能。
场景 3:Load Tail 与 Load Head 不同步
从原理上讲,tail < head
这种情况绝对不可能发生,但不同线程的视角看到的结果很可能不同:
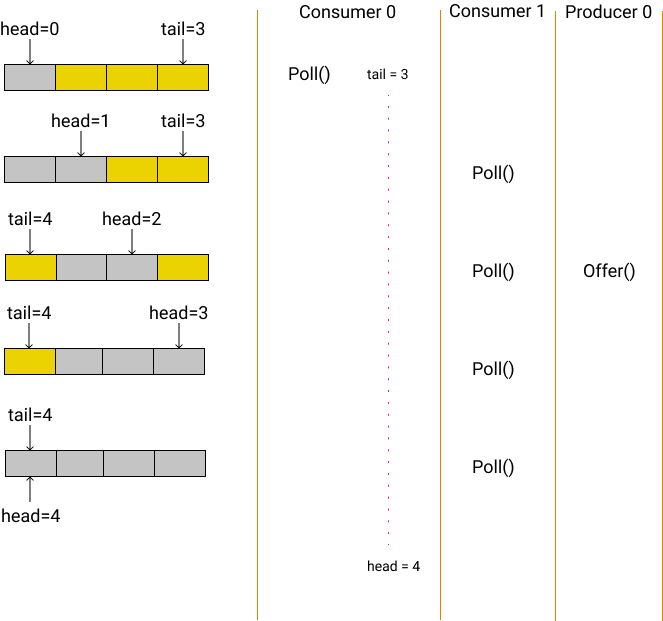
正如上图所示,Consumer 0 在读取了 tail=3
后,本应继续读取 head,但由于被调度器出让
cpu,在一段时间内其他几个线程已经执行了数次操作,等到
Consumer 0 再次获得 cpu 后,它读到
head==4,因此在 Consumer 0的视角看,此时的
ring buffer 出现了”不可能“ 情况:tail==3, head==4。
重要的是:目前实际上 tail==head,表示 buffer
已经全部被读取,不包含有效数据了。但显然在 Consumer 0 看来
tail - head != 0,所以它不认为 buffer
已经为空,这时它继续工作,只要前一次对 head=4
的消费还没有彻底结束(还未将值设置为
nil),Consumer 0
就会读到错误的数据,产生重复消费。
因此我们要修改 isEmpty:
1 | func (r *ring) isEmpty(tail uint64, head uint64) bool { |
反过来,从Producer的角度看,实际上 Offer()
的过程中,也同样会出现 tail < head 的情况,但不同的是
Offer() 的 CAS 是对 tail++,因此只要不是最新的
tail,都无法成功的 CAS。 所以 Offer()
的时候不会因为 tail < head 而写入新数据覆盖旧数据。
但是由于我们可以预见到但凡 tail < head 那么
Offer() 一定不会成功,所以 CAS
之前的操作也没必要再做,因此可以再修改 isFull():
1 | func (r *ring) isFull(tail uint64, head uint64) bool { |
性能测试
经过前一节的改造之后,我们的 lock free ring buffer 在并发访问上已经没有问题了,那么接下来我们就会思考:
搞了这么半天,lock-free 的实现与常规的有锁队列相比,性能是否有提升?提升了多少?
由于 ring buffer 本身通常只会作为系统中的一小部分,其性能表现和使用方有很大关系,因此我们在性能测试中,应做好如下的准备:
- 性能测试代码应尽量排除外部因素的干扰
- 需要提供一个比较基准,作为对照组
测试本体
完整的测试代码请见这里。
1 | func mpmcBenchmark(b *testing.B, buffer lfring.RingBuffer, threadCount int, trueCount int) { |
使用 go-bench
的并行测试来测试性能,manage() 函数用于通过一个
controlCh 来控制实际创建的 go-routine 到底是
producer 还是 consumer,我们可以用 threadCount 和
trueCount 两个参数来控制实际创建的 go-routine
总数以及其中 producer 和 consumer 的比例。
对于 producer,生产的数据从一个预先创建好的数组中依次获取。对于
consumer,为了最大程度的排除消费速度对生产速度的限制,consumer
直接将读到的数据丢弃,此外还维护一个
counter,来记录所有消费线程总共成功消费的次数,该 counter 使用
atomic.AddInt32(&counter, 1) 实现。
因此,对于性能测试结果的比较,counter 值越大,说明在相同时间内完成的 ”生产 - 消费“ 过程次数越多,性能也就越好。
基准
我们直接将 go channel 包装为一个基准
buffer,来作为对比。我们知道 channel 的底层是用一个
mutex
互斥锁来保护数据的,因此在发生竞争时竞争失败的线程会排队等待。
包装后的channel如下所示:
1 | type fakeBuffer struct { |
对比
lock-free ring buffer 与 channel
的性能测试,采用上述性能测试代码(capacity = 16, thread = 12),执行
1s,分别执行 100 次取3σ 平均值。
对比结果如下:
| Type | Counts |
|---|---|
| Lock-free ring buffer | 5, 744, 963.03 |
| Channel | 2, 670, 051.37 |
可以看到,性能测试表明,限定在前述代码的场景下,我们的 lock-free 方式比有锁方式快约 2 倍。
对比另一种实现
除了本文的实现以外,还有一种改进的实现方式(来自
Dmitry Vyukov,golang 的抢占式调度器的贡献者),将每个元素抽象为一个
Node 节点,节点中包含一个计数器,类似于该节点的一个
stamp,每次读/写都会修改对应节点内的 stamp,这样在 Offer()
和 Poll() 的时候就无须判断整个 buffer 是否
full/empty,而是直接判断当前节点的 stamp 是否与 head/tail
相等,若相等就表明可以操作,反之亦然。
对应的 go 代码可见这里。
我们可以注意到在这种实现中,结构定义里通过一些 _padding
来与 CPU 的 cache line 对齐,由于这种实现的特点,Offer()
的时候只需要读写 tail,Poll() 的时候只需要读写
head,因此将tail 与 head
分布在不同的 cache line 中有利于更高效的利用 CPU 缓存(stamp 和 value
都包含在 Node 中,也能得益于 cacheline 快速读取)。
但相比于本文的实现中,head/tail
是同时读,分别写,并且由于各种检查条件的存在,读的次数远多于写。因此head和tail处于同一个
cache line 内反而可以提升读性能(性能测试表明,对于采用
node 方式的实现,_padding 能够提升大约
12%,而本文实现中,_padding 会导致性能降低 13%
左右),因此也就不需要 _padding 了。
不同参数下的性能对比
Threads = 12,Producer : Consumer = 1:1,Capacity = [2, 4, 8, 16, 32, 64, 128, 256, 512, 1024]
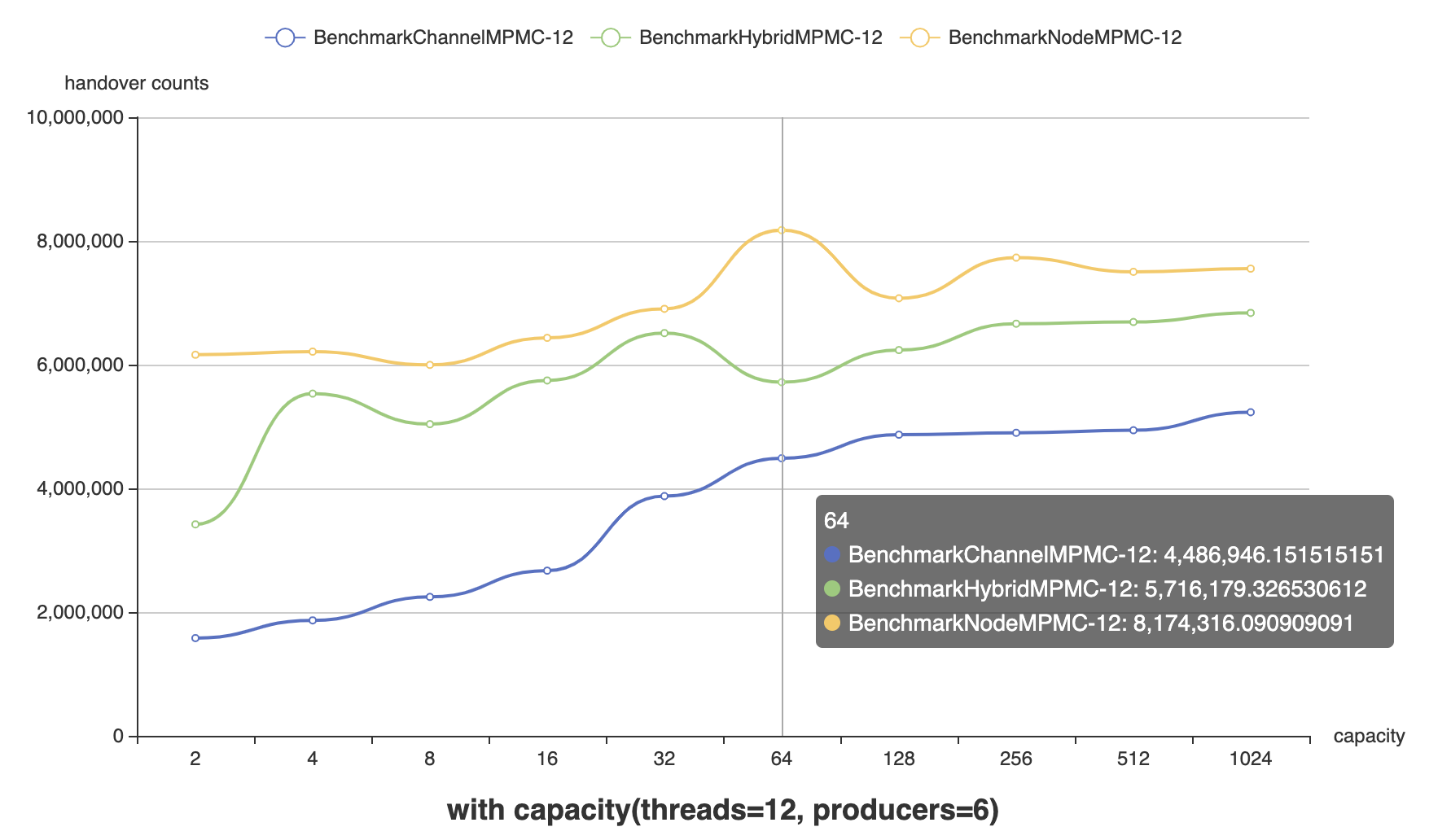
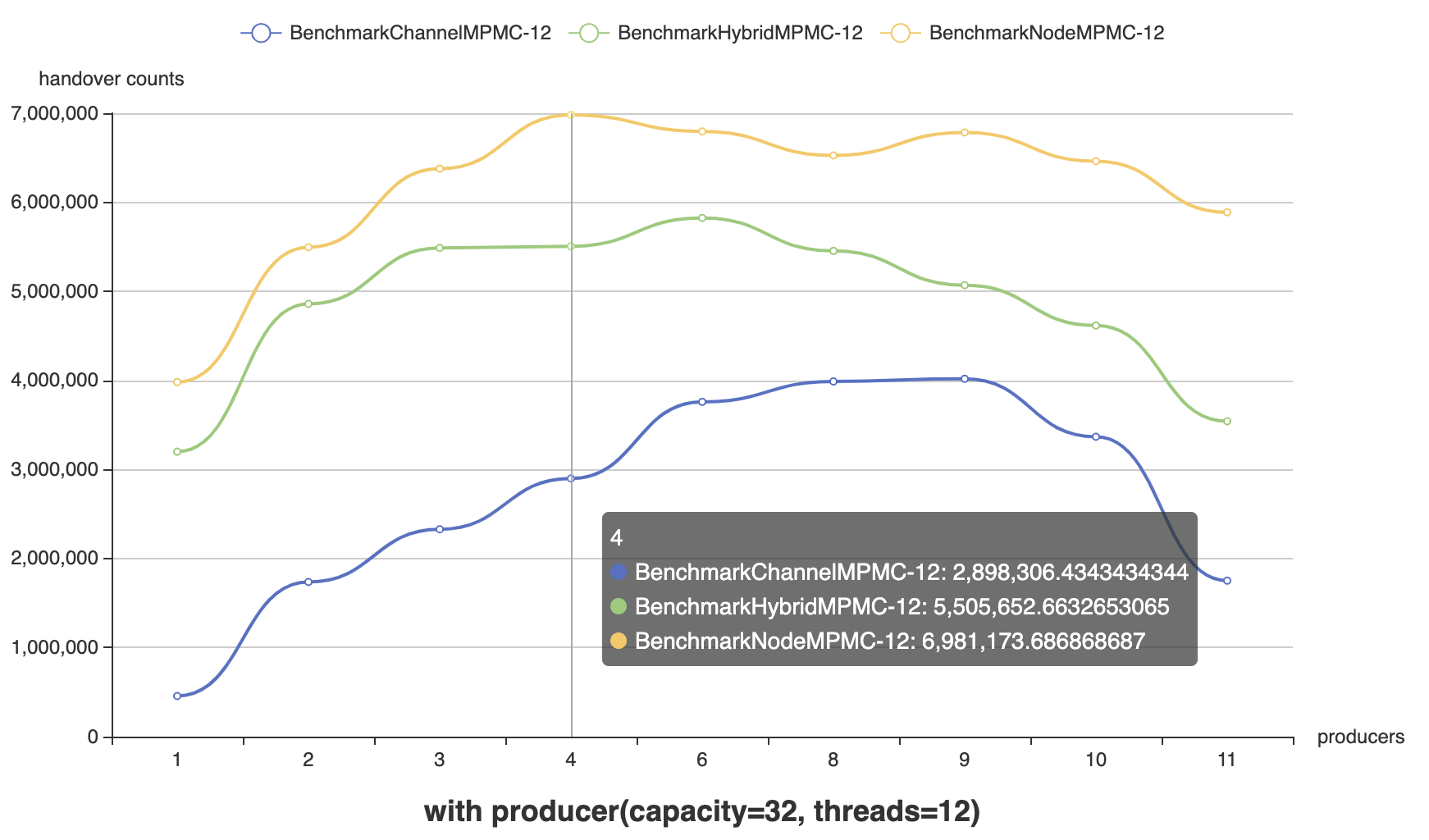
Threads = 12,Capacity = 32, Producer : Consumer = [1:11, 1:5, 1:3, 1:2, 1:1, 2:1, 3:1, 5:1, 11:1]
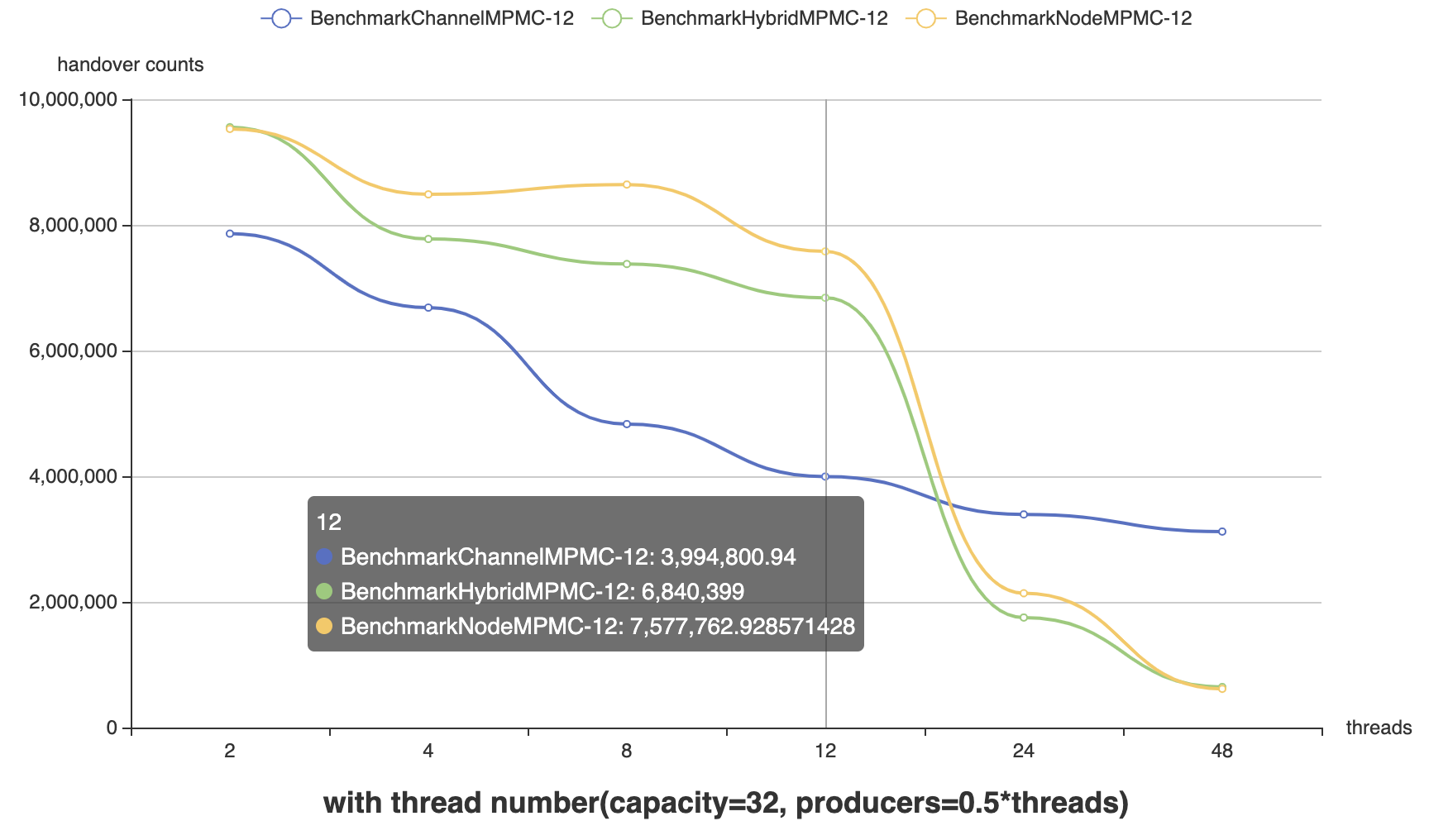
Capacity = 32, Producer : Consumer = 1:1,Thread = [2, 4, 8, 12, 24, 48]
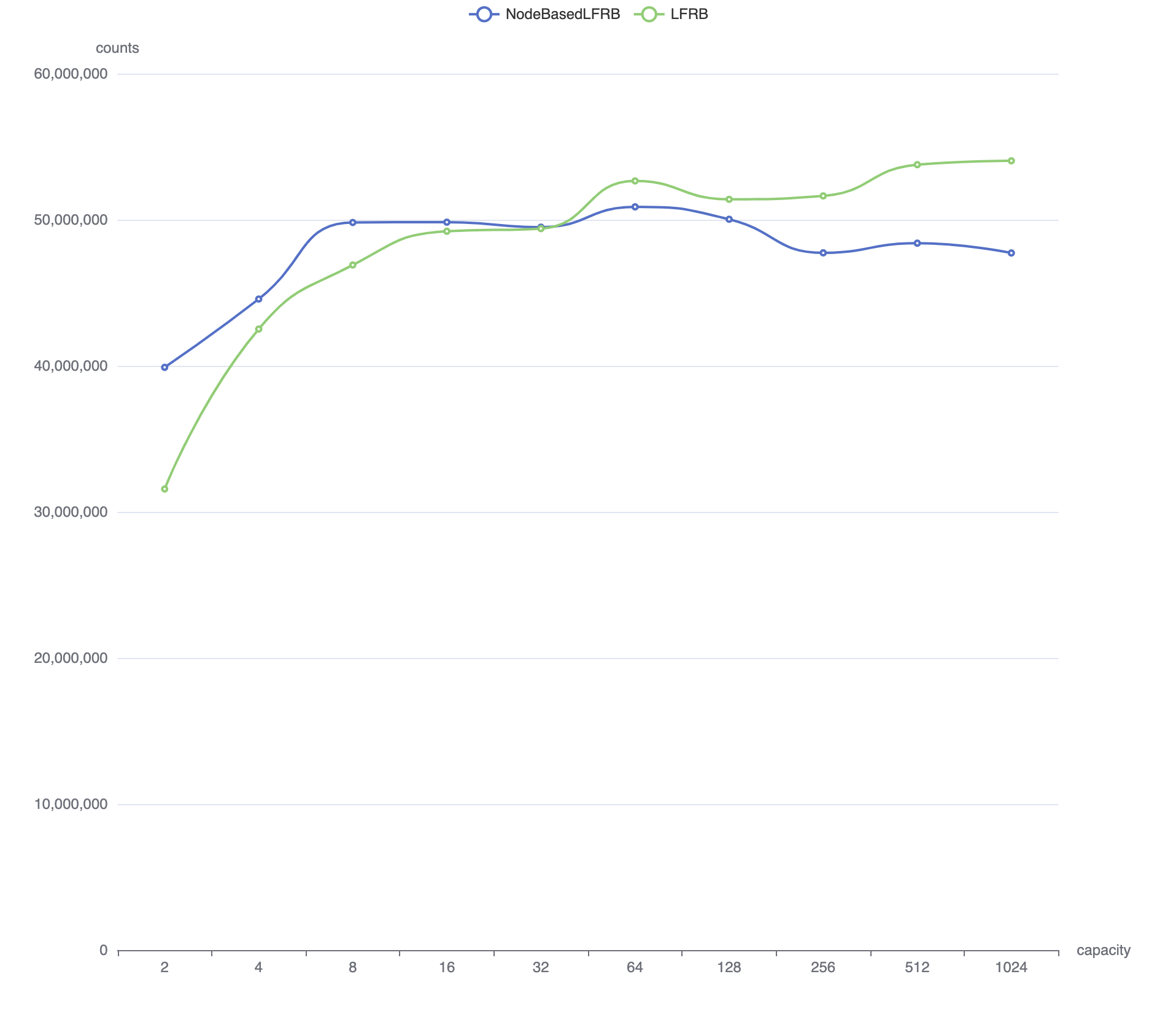
可以看出改进版方案显然更胜一筹,进一步的测试表明,对 Cacheline 的优化起到了显著的效果,下图是 NodeBasedLFRB 不进行 Cacheline 优化时的性能对比(本文的实现作为对照):
<--  -->
-->
显然没有优化过的性能与本文方案不相伯仲。
不论是从 go
代码,还是从编译后的汇编代码来看,改进版和初始版实现之间的主要区别都在于改进版通过多记录了每个节点的
step 从而减少了一次
if..else..(可以减少一些分支预测错误导致的时间惩罚),除此之外并无区别。但正因为
step 的存在隔离了 head 与 tail
的读写,因此得以采用 Cacheline 来优化对这些共享变量的读写。
另外,由于无锁的特性,从上面不同线程的对比图中我们发现,当线程数(测试中是直接设置了 P 的数量,因此可以近似认为这里的线程数是操作系统线程数)超过 CPU 数量时(测试机器是6核,超线程后 12 个逻辑核),由于对 CPU 资源的竞争,导致性能急剧下降(考虑是线程调度成本),反倒是 Channel 通过互斥量排队的方式更胜一筹。
MPSC 与 SPMC
在很多场景下,我们面对的可能是 MPSC(multi-producer single-consumer)或是 SPMC (single-producer milti-consumer)的场景。我们可以利用这些特定的场景,来简化一些不必要的操作,从而达到提高性能的目的。
修改 ring buffer,分别得到上述两种场景下的实现方案:
1 | func (r *hybrid) SingleProducerOffer(valueSupplier func() (v interface{}, finish bool)) { |
性能对比
Threads = 12 (SPSC 下 Thread = 2),Capacity = 16
| Type | Optimization Counts | Original Counts |
|---|---|---|
| MPSC | 56168349.1 | 40081057.2 |
| SPMC | 12947559.1 | 14480503.2 |
| SPSC | 44195353.5 | 111587717.1 |
有趣的是在 MPSC 的场景下,优化后比优化前性能提升了约 1.4 倍,然而在 SPMC / SPSC 的场景下,性能却有所下降(SPSC 竟然下降了约1.5倍)。
结合前面的性能测试我们能够发现,我们的方案在 producer 数量少于 consumer 时,性能会急剧下降,反之却影响不大。因此想要搞清楚得到上面测试结果的原因,还是应该更细致的分析初始方案在 producer 更少的情况下性能差的原因,不过目前这部分工作还没有进展,本文会持续更新。