AI 时代的软件工厂管理框架
传统软件开发是"手工作坊"
软件开发的本质是知识在不同形式下的传递——需求被转化为设计,再被转化为软件,软件开发是知识通过开发者发生重组的过程。
这种转化的过程知识密度很高,导致软件开发深度依赖人脑的参与,让软件开发者更像是手工业者,软件开发更像是做手艺活。当我们以手工业的视角看待以往的软件行业时,会很熟悉以下的现象: - 横向扩展困难: 给一个已经延迟的项目增加人手,往往使项目更加延迟 - 产物高度依赖个人: 同样的功能需求,不同开发者开发的效率、质量差异巨大 - 过程可见性差: 开发者脑中的认知过程是黑箱,交付时只能看到输入(需求)和输出(代码),中间过程不可见也不可控 - 不确定性贯穿始终: 几乎没见过按计划交付的软件项目,其时间、风险、质量皆难以准确预估 ## AI 引发的范式转移 《没有银弹》中提到:软件开发的复杂性可被区分为本质复杂性和偶然复杂性,偶然复杂性可以被工具降低,但本质复杂性无法消除(有意思的是《没有银弹》发表至今已经40年,但其内核看起来仍然成立)。
AI 似乎也不是银弹,但软件开发确实变了。偶然复杂性有望被全面解决,人类的工作面会提升到更高的抽象层级:只关注本质复杂性。
当AI能够承担编码执行、测试生成、代码审查、甚至大部分架构设计和需求分析工作时,软件开发可以不再是手工作坊,“认知契约” 会成为人与机器之间的规格图纸和双向协议,人定义意图和约束,机器反馈可行性和成本。
软件工业化随之而来:执行层可以被标准化、可预测、可规模化地替代,从而使管理层(人)能够从执行中分离出来,专注于更高层级的流程设计、质量体系和持续优化。
那么当软件开发具备了工业化管理的前提条件时,是否有可能构建一个适用于AI时代的软件工厂管理框架? ## 软件工厂管理框架
在讨论管理框架之前,首先要问:我们要管理什么?为什么要管理?
当软件研发中大规模引入 AI 协作后,可以预见的有: - 产出代码的边际成本大幅降低,但相应的让人类的决策和注意力成本大幅上升 - AI 基础设施方便扩缩容,人力编排不再是难题,人类需要适应频繁上下文切换 - 与人类开发者不同,智能体没有长期记忆,领域知识共享和记忆管理会非常重要 - 由于上下文窗口长度的限制,AI 存在认知漂移和产出物不一致的问题 - 智能体的工作过程完全可观测,对生产行为进行细粒度监控和优化成为可能
因此,软件工厂的管理维度应聚焦于: - 如何提升人类的认知和决策质量 - 如何确保生产的一致性 - 如何让知识和信息被充分共享 ### 三层框架 完整的软件工厂框架是一种三层结构:
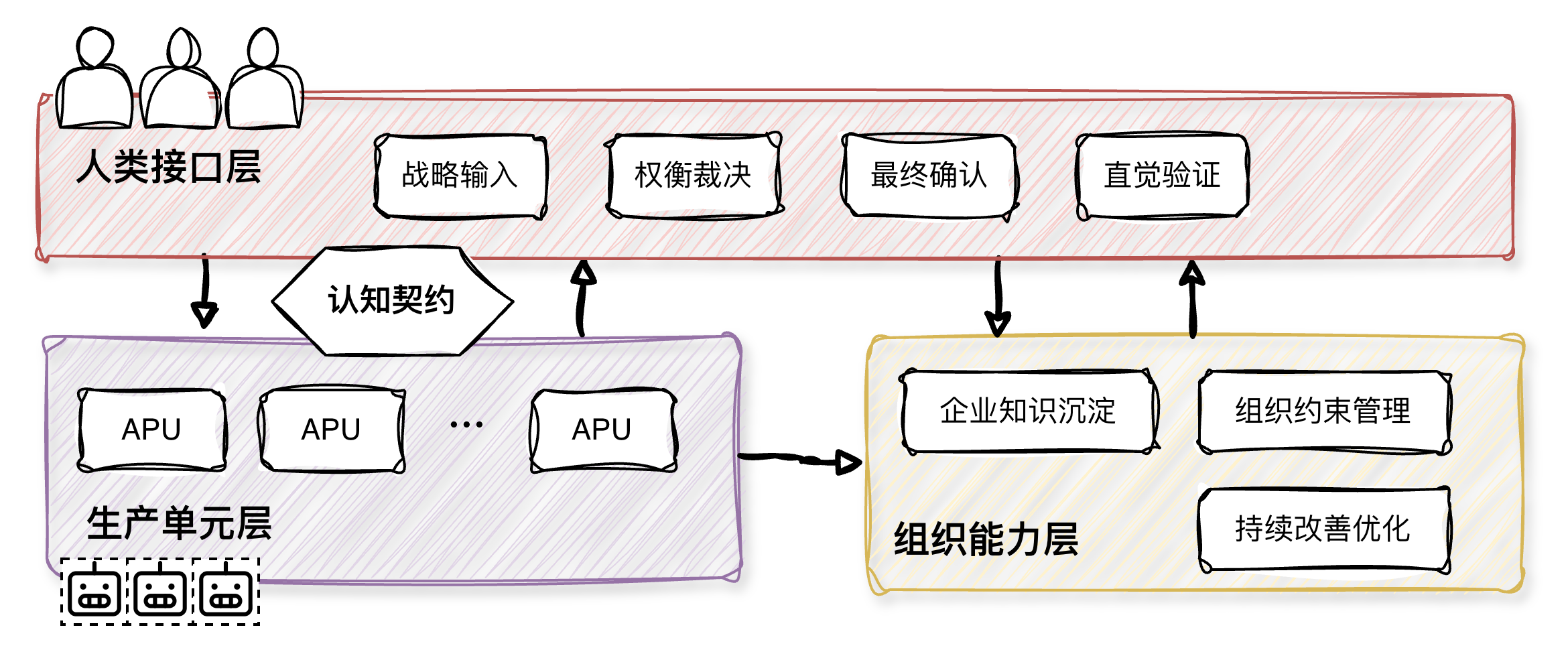
生产单元层: 这一层由各种 APU(Agentic Production Unit)来组织智能体进行协作和生产,负责不同任务的 APU 会有些许差异。 这一层的目标是最大化释放AI的生产力,同时依靠生产单元和组织层面的体系来约束产出,确保生产一致性。
组织能力层: 这一层的核心目的是定义跨APU的能力和活动,例如行业知识和合规性约束,架构规则和生产规范,生产效率持续观测和改善等。 这一层本质上是聚合了企业核心的数据资产,且具有资产迭代的能力。人类和APU都依赖这些数据资产来处理自己所在层次的工作。
人类接口层: 这一层将人类的价值聚焦在方向感、判断力和创造力的活动上,例如战略输入,权衡裁决,最终确认,直觉验证等。通过人类接口层的隔离,生产细节被屏蔽掉,人类重点关注数据和决策,只在需要时才介入生产流程。
生产单元层
生产单元层封装了实际执行工作的各类 APU,而 APU 推进生产的核心是围绕 Playbook 构建的智能体。这些智能体在 APU 中按照设定的工序将原料变为产物。
Playbook 是为确保智能体高质量地将输入转化为产出而设计的完整管理规范,它定义了软件工厂中不同“工种”为了完成其特定工作所依赖的要素,包括工序、约束、工装和反馈的组合: - 工序(Process)是Playbook的核心,它定义了具体的操作步骤序列 - 约束(Constraint)定义边界,是不可违反的规则和限制 - 工装(Fixture)是智能体可用的各种辅助工具如Skills,MCPs等 - 反馈(Feedback)描述了需要回传和分析的数据,用于持续改进
这里以 “软件交付 APU” 举例说明 APU 的工作方式:
软件交付APU封装了包括需求拆解,代码生产,质量保障等几个核心的Playbook。
它开始工作的前置条件是明确的 “认知契约”: - 提供需求说明书以确认交付范围,提供架构设计文档以确认技术路线 - 无论契约的形式,其内容应意图清晰、约束明确、验收标准可判定
整个APU的工作流遵循标准的迭代式开发流程: 1. 需求拆解智能体:基于输入将交付目标拆解为Story列表,过程中涉及的领域知识可以在组织知识库中搜索获取,对需求和架构的质疑会拉起产品APU和架构APU的流程进行澄清。 2. 代码生产智能体:围绕 Story 进行开发,验证,集成等工作。生产代码期间遵循架构,安全,合规等约束,涉及技术,架构层面的冲突则引入架构APU来给出决策。智能体之间互相评议代码,提出修改意见。代码通过门禁检查后直接集成并部署。 3. 质量保障智能体:对部署的功能进行验证,提供测试结论。每到阶段性里程碑时,通知人类对可运行的软件进行验收,验收期间被确认的问题和改进重新形成Story加入Backlog。
工作期间所形成的Story,设计图,代码,沟通总结,ADR,Review记录,验收记录等全部作为APU层面的上下文,可用来初始化或恢复智能体的记忆。 工作期间上报的各类相关的信息,例如Story完成的时间,讨论和对抗的次数,被反复修改的代码块,被打破的约束等,会持续被反馈上报,用来支撑数据分析。
组织能力层
组织能力层定义了跨APU的能力和活动,这些能力和活动能帮助人类和 APU 理解业务,明确边界和约束,以及对生产过程进行持续改善。
企业知识沉淀 一个金融科技公司和一个汽车制造公司,虽然都在做软件开发,但其组织能力、合规要求、质量标准是截然不同的,为了让软件工厂能开发符合企业需求的软件,智能体需要理解企业实际的业务,这是知识沉淀的目的。
从软件工厂的维度看,建设企业知识沉淀能力是为了服务智能体,但事实上知识沉淀的前提是数据治理。为了让智能体能找到准确的信息,同时又避免发生数据泄露等安全问题,对数据治理应当关注知识架构,数据质量,动态更新,权限隔离等方面。
组织约束管理 由于智能体本身的非确定性特点,任由智能体发挥所产出的产物通常都会和需求大相径庭。为了确保软件工厂产出的一致性和可预测性,需要通过约束来控制整个生产过程,防止漂移。Playbook 中的“约束(Constraint)” 是其关键元素,用来定义智能体工作和产出物的边界,这些约束的来源正是组织约束管理所提供的内容。
有约束就必须要确保约束被遵守,约束包括指导性和强制性两类: - 指导性约束:基于Playbook中的约束,指导智能体的生产,同时智能体之间也相互进行对抗检查 - 强制性约束:通过linter,checker,pipeline 等工具,强制对产物进行门禁检查
持续改善优化 由于智能体工作过程的高透明度,让软件工厂能以比人类团队细致的多的层面对生产过程进行观察。这种观察能在生产一致性和质量提升层面提供巨大价值。
可参考以下关键指标来评估软件工厂生产的一致性和质量:
| 维度 | 指标 | 含义 |
|---|---|---|
| 功能一致性 | 功能行为等价率 | 两组不同智能体对同一需求的实现,在相同输入下输出是否一致 |
| 效率一致性 | 成本等价率 | 两组实现在相同模型和负载下的token消耗和基础设施费用是否接近 |
| 缺陷密度 | 千行代码缺陷率 | AI生成代码的缺陷密度趋势 |
| 第一次通过率 | 无需返工的比例 | 代码生成后直接通过所有质量门禁的比例 |
人类接口层
回到文章开头的判断,我们期望 AI 能够帮助我们解决掉软件开发中的偶然复杂性,让人类能专注于本质复杂性的解决,因此人类接口层的目的就是为了给人类提供一个管理视角,提供人与AI在不同工作面之间的交互接口。例如,需要人类参与的典型场景有:
| 参与类型 | 触发条件 | 人类角色 |
|---|---|---|
| 战略输入 | 项目启动、方向调整 | 定义Why,设定约束和优先级 |
| 权衡裁决 | 对抗无法收敛 | 在多个方案中选择,承担决策责任 |
| 最终确认 | 质量门禁通过前 | 确认交付物符合预期 |
| 直觉验证 | 探索性测试阶段 | 发现AI无法察觉的体验和感受问题 |
人类通常更习惯于持续做一件事,但站在管理视角下,人势必会面临频繁的上下文切换。所以对于人类的参与和介入体验也需要有充分考量,例如更多的采用图形化方式描述问题,通过多轮对话牵引更深入的思考,提供建议和推演帮助分析等等。
下一步
基于前面对三个层次的解释,我们可以将开始的管理框架简图更新为如下的详图:
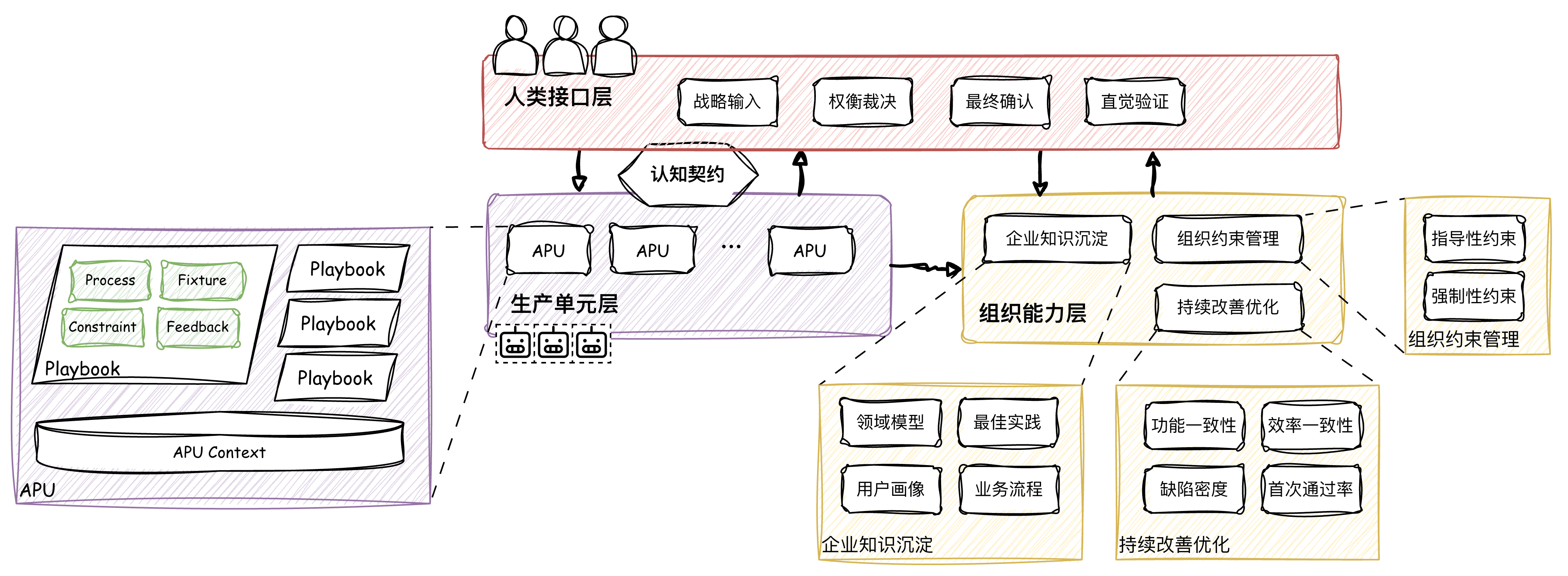
不过,前面讨论的软件工厂管理框架,主要聚焦在概念层面,具体的设计考量尚未深入,后续我们将将层层递进,逐一讨论并细化。