虚拟工厂:Java stream
在我的文章 虚拟工厂:Java 线程池 中简单介绍了采用
”工厂“ 这样一个现实生活中的概念来抽象具体的线程操作,并定义了
Worker TaskQueue
等概念。用这种方式拉近了计算机域和真实世界域之间的距离,让代码表现现实的意图。
不仅仅是线程池,从 Java 8
开始引入的Stream也一样,它用代码构建了一套流水线体系,通过流水线环节的叠加来实现对流水线上元素的各种处理。
流水线(Pipeline)
在中文翻译中,我们时常会把 Assembly Line(装配线)以及 Pipeline(管线)都译为流水线,而在计算机领域,我们说的流水线通常都是 Pipeline,例如 CPU 的指令流水线(Instruction Pipeline)。
对于 Pipeline,韦氏词典的第一个解释即:
a line of pipe with pumps, valves, and control devices for conveying liquids, gases, or finely divided solids
显然对于上述释义,Pipeline 翻译为 “管线” 似乎更为合理,不过在软件领域,对 Pipeline 进行了引申,一个 Pipeline 是一组计算过程(computing processes)的组合,并且以并行(Parallel)的方式执行。
那么实际上在计算机领域,Pipeline 与 Assembly Line 在概念上就没有太明确的区别了:我们可以将之类比为一种操作,它可以由多个工序构成,每个工序都将对上一个工序产出的工件进行进一步加工,工件从流水线入口进入,并在流水线上移动,最后被输出为某种产品。
所以根据上述描述我们可以抽象出与流水线相关的几个概念:
- 工件(workpiece):即被流水线加工的元素
- 工序(process):即执行单元,它以工件为输入,也以工件为输出
- 流水线(pipeline):即流水线主体,他包括了入口,出口,在其上可以放置各种工序
那么我们就能得到如下的一个流水线结构: 
可见流水线上的工序理应能够灵活的组合与替换,采用各种简单而固定的工序,就能组合出来满足多种多样的需求。
Stream
Java 8 中定义的流式操作,能够对流(Stream)叠加多种操作并进行处理。在 Processing Data with Java SE 8 Streams, Part 1 中提到对 Stream 的定义:
a sequence of elements from a source that supports aggregate operations.
首先,任何单一对象、集合、数组都可以输入为一个 Stream,这就是定义里提到的 “source”。转换为 Stream 后,他们都将变身为流中的一个元素,即 “sequence of element”。在对所有元素进行一番处理之后,Stream 可以再次转换回到对象、集合、数组等,这里的处理即 “aggregate operations”。
那么,对于这 ”一番处理“,从处理的方式上划分,有以下几种处理形式:
中间操作(Intermediate Operations):会返回一个新的 Stream,并且是 Lazy 操作
无状态操作(StatelessOps):对单个元素进行操作,操作之间没有联系,也不保存任何元素的状态。典型操作有:
filtermaappeak等有状态操作(StatefulOps):对流中元素的处理会依赖之前处理的结果,元素与元素之间有关系,下一个元素的处理依赖上一个元素的状态,或需要获取到所有的元素后才能进行操作。典型操作有:
distinctsortedlimit
终止操作(Termination Operations):穿越(traverse)整个流,得到结果或是副作用(side-effect),一旦执行了终止操作,整个流就认为已经被消费,并且无法再次执行任何操作。
Stream Shape
通常,Stream 中的元素都以对象引用的形式存在,但同时 Java 也考虑到了对基本类型的 Stream 支持,因此共定义了四种 “Stream Shape”:
- Reference:元素类型为对象引用,其行为由
Stream定义 - Int Value:元素类型为
int,其行为由
IntStream定义 - Long Value:元素类型为
long,其行为由
Longtream定义 - Double Value:元素类型为
double,其行为由
DoubleStream定义
下文中主要以 Reference 类型的 Stream 来举例说明流水线的工作原理。
ReferencePipeline
对于元素为对象引用的 Stream(也是大多数 Stream
的形态)而言,ReferencePipeline 是其实现的核心。
ReferencePipeline的类继承关系如下图所示:
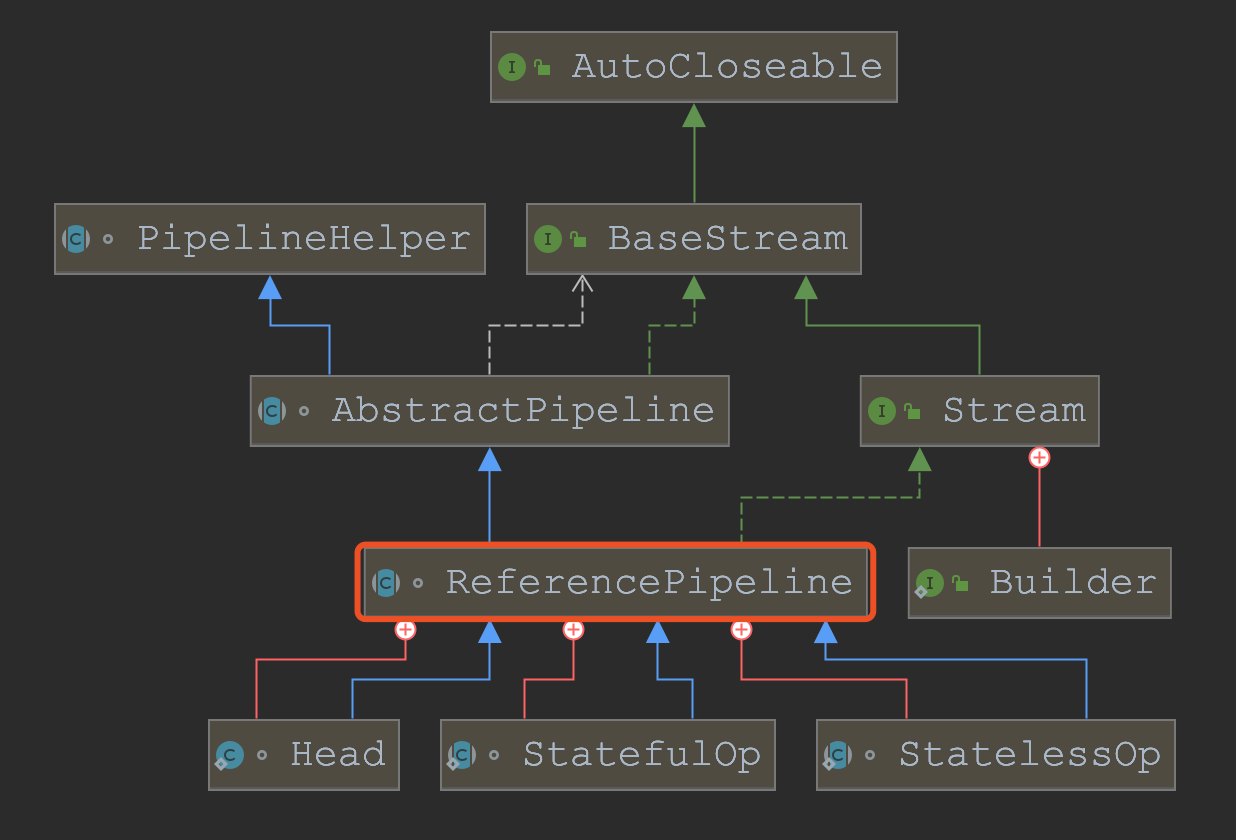
此外,由于ReferencePipeline本身实现了
Streaam接口,因此他实现了Stream中定义的所有行为,包括:map,filter,reduce,collect,limit
等等。所以我们可以说ReferencePipeline本身就是一个流水线的基础工序,基于这种基础工序,我们能构造出多种多样的工序来。
ReferencePipeline
作为基类,在其内部提供了如下三个实现类,这三个实现类进一步对不同种类的工序进行了定义:
- Head:入口工序
- 与其他两个实现类相比,
Head比较独特,也比较好理解:他会被作为整个Stream的头部,也即流水线的入口。又因为Head本身是一个ReferencePipeline,因此我们可以把Head理解为一道特殊的工序,他接收原料作为工件,且不对工件做任何进一步处理,但作为头部(第一道工序),我们可以在其之后追加更多的工序。
- 与其他两个实现类相比,
- StatelessOp:无状态工序
- 对应前文 ”中间操作“ 中的无状态操作
- 无状态工序不依赖前后两个工件的状态,即不论前后工件如何,他只对当前工件进行加工,典型的无状态工序是
map
- StatefulOp:有状态工序
- 对应前文 ”中间操作“ 中的有状态操作
- 有状态工序依赖与工件之间的状态,他能结合多个工件来进行处理,典型的有状态工序是
sorted
通过上述三种基于 ReferencePipeline
实现的操作,定义了构造一条流水线的入口(Head)及中间操作(intermediate
operation),那么现在就只剩下流水线的出口(terminal
operation)还没有定义了,所以,JDK
中还对流水线的出口即终止操作进行了定义:
- TerminalOp:出口工序
- 对应前文”终止操作“
- 将流水线各工序最后输出的工件进行整合并转换为产品,典型的终止操作是
reduce与collect
综合上述几种操作类型,不出意外,我们也许能进一步想到:
map操作其实就是一个行为是 ”对工件进行映射变换“ 的StatelessOp工序filter操作其实就是一个行为是 ”对工件进行筛选“ 的StatelessOp工序limit操作其实就是一个行为是 ”只保留有限个工件“ 的StatefulOp工序sorted操作其实就是一个行为是 ”对所有工件进行排序的“ 的StatefulOp工序collect操作其实就是一个行为是 ”将所有工件整合为产品“ 的TerminalOp工序
因此我们日常使用的形如:
1 | Stream.of("a", "b", "c", "1", "2", "3").filter(NumUtil::isNum).map(NumUtil::minusOne).limit(1).collect(Collectors.toList); |
其实就是先创造了一条这样的流水线:
Head -> StatelessOp:filter ->
StatelessOp:map -> StatelessOp:filter ->
StatefulOp:limit -> TerminalOp:collect
之后输入工件:"a", "b", "c", "1", "2", "3",最后启动流水线产出结果。
流水线的组装
入口:从原料到工件
我们知道,在期望对某个或某集合进行 Stream 操作之前,我们都需要使用一种通用的方式,将元素或集合转换为 Stream,这种转换方法通常包括:
Stream.of(T value):将单个给定元素转换为 StreamArrays.stream(T[] valueArray):将数组转换为 StreamCollection.stream():将集合转换为 Stream
深入这些方法后我们发现,实际上他们最终都调用了如下方法:
1 | public static <T> Stream<T> stream(Spliterator<T> spliterator, boolean parallel) { |
该方法很简单,如前文所述的,构造流水线的前提是构造一个入口,即Head,因此不论是从单个对象,还是从数组、集合中构造流水线,我们都将创建一个入口Head。
那么入口有了,怎么样将原材料(输入元素)作为工件导入流水线呢? 就靠
Spliterator。
Spliterator定义了一类行为:
作为 Stream 的输入源,Spiltertor 能够对元素进行遍历(traverse)或拆分(partitioning)。
可以采用
tryAdvance(Consumer<? super T> action)方法来将 action 作用于当前元素,可以用
void forEachRemaining(Consumer<? super T> action)方法来将 action 作用于所有元素。
在真实的使用中,流水线工序的集合从外部可以看做是一个Consumer,而Spilterator正是采用forEachRemainig()方法遍历每一个元素并执行流水线Consumer.accept()的方式来实施流水线操作的。
中间操作:有状态 vs 无状态
StatelessOp 无状态
每一个中间操作都会在当前流水线末端增加一道工序。
我们从最简单、最容易理解的操作map来看看到底怎么样给流水线增加一道工序:
1 |
|
我们知道,map操作会对流水线上每一个工件进行相同的加工工作,具体的加工方法描述为一个Function<? super P_OUT, ? extends R> mapper,所以显然map是一种无状态操作。上述代码中也印证了这一点:
对一个ReferencePipeline(可以假定当前是一个Head)实施map操作实际上是返回了一个StatelessOp的匿名子类。那么在哪里做挂载工序操作呢?看看StatelessOp的构造方法:
1 | // StatelessOp |
根据代码可知,创建的
StatelessOp实例,在构造函数中以调用者(刚刚我们假定为Head)this
作为其upstream(也就是 AbstractPipeline
中的previousStage)这有点像是构造链表时,新增节点将其previousNode设置为尾结点,并将尾结点的nextNode指向自己一样。
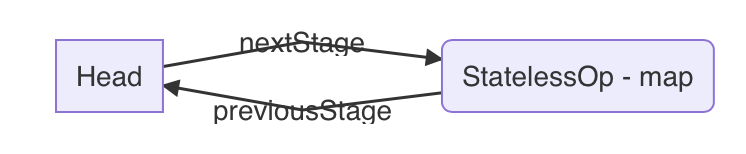
至于匿名类中复写的opWrapSink方法,我们可以暂且认为该方法会在最终流水线启动时对每一个工件调用,因此也就不难理解方法内构造了一个Sink(Sink
是什么后文会讲到),在Sink中又通过downstream.accept(mapper.apply(u))来对工件(也就是输入参数u)apply
了 mapper,并继续调用其下游的accept方法。
明白了map是怎么一回事,filter也就显而易见了:
1 |
|
filter除了具体的操作与map不同以外,仍然是构造了一个StatelessOp的匿名类。并且结合filter的语义,确实是当predicate.test(u)为
true
时,才会继续执行下游的操作,否则什么也不做。通过这种方法简单的实现了筛选功能。
StatefulOp 有状态
在来对比的看一下有状态操作limit:
1 |
|
很直白:将 limit值赋给m,
每当执行一个工件时m--,直到m<0后不再继续操作。这里的
"Stateful" 说的就是m了。
出口:完成组装
在对流水线添加了一系列工序之后,是时候启动流水线并生产出产品了。
我们通过对流水线挂载最后一个工序:TerminalOp来结束流水线的创建,并启动流水线。先来看看TerminalOp提供的行为:
1 | interface TerminalOp<E_IN, R> { |
除去我们不关心的行为,最重要的行为便是:evaluateSequential()了,根据注释可知,实现该方法,来对给定的spliterator执行操作,操作是由描述了上游中间操作的PipelineHelper来执行。根据前文的继承关系图,我们知道实际上ReferencePipeling本身就是一个PipelineHelper,再结合前文所述,一条流水线被创建时,spliterator已经与Head一起被作为流水线入口的一部分了,因此直接找一段比较简单的终止操作实现,reduce:
1 | // ReferencePipeline |
可以发现,当我们对一个 Stream
挂载reduce操作时,实际上先构造了一个ReduceOp(实现了
TerminalOp)之后通过语句terminalOp.evaluateSequential(this, sourceSpliterator(terminalOp.getOpFlags()))
触发TerminalOp中的evaluateSequential()方法,其两个入参正好是当前组装好的流水线this以及输入源sourceSpliterator()(该方法返回一个Spliterator)。
那么我们具体来看一看ReduceOp中定义的`evaluateSequential():
1 | private abstract static class ReduceOp<T, R, S extends AccumulatingSink<T, R, S>> |
结合前面reduce方法构造的匿名类中实现的makeSink()方法
return new ReducingSink();,我们得知其实reduce匿名类的真实作用是调用makeSink构造了一个Sink之后将之传入原
Stream
中,并调用流水线的wrapAndCopyInto()方法来启动整个流水线。
Sink
前文我们在构建中间操作时遇到过Sink但没有细说,终于,要到了解释Sink的时刻了。
从流水线的角度讲 ,不论是 map、filter、
limit 还是
reduce,都属于高层抽象概念,主要用于定义通用的工序行为。在
Stream
的实现中,采用Head、StatelessOp、StatefulOp和TerminalOp作为中间层抽象,主要用于对工序行为进行归纳分类。而最终落到低层实现上,靠的只有一种东西:Sink。
从Sink的定义来看,不论是什么样的流水线工序,Steam
都将其低层定义成了一个Sink,用来在流水线的各个阶段(stage)传递值。从名称中就很明确,Sink就像是一个个的水槽,互相之间首尾相连,数据流从第一个水槽漏到第二个,再漏到第三个,以此类推,只能向下漏,不能向上返。

Sink具有两个状态:
- 初始态
- 激活态
三种基本的行为:
- begin: 在接收数据之前调用,并将
Sink置为激活态 - accept:开始接收数据,并对数据进行处理
- end:数据处理完成后调用,并将
Sink置为初始态
有了以上知识,结合前文map操作的实现:
1 |
|
就很清晰了,就像前文图里画的一样,通过opWrapSink方法,把传入的sink进行一层包装,创建一个新的Sink.ChainedReference(有点像装饰器模式)。来看看Sink.ChainedReference的实现:
1 | abstract static class ChainedReference<T, E_OUT> implements Sink<T> { |
基于传入的Sink构造的Sink.ChainedReference,顾名思义就像一根链条一样,其begin和end方法都直接调用传入Sink的方法,在map的opWrapSink中,覆写了accept()方法,先执行mapper的逻辑,之后执行传入Sink的逻辑。
有趣的是,在Sink.ChainedReference中将传入的Sink命名为"downstram",也就是下游,那么从实现上,Sink是从最底层开始,层层包装,层层向上构建的。而前文中我们提到,Sink就像是首尾相连的水槽,水(数据)只能向下流,不能向上流。正因为这一点,实际上Sink在组装时,是从下往上,才能满足运行时数据从上往下流动。
基于此,我们是否可以假设,类似Stream.of("a", "b", "c", "1", "2", "3").filter(NumUtil::isNum).map(NumUtil::minusOne).limit(1).collect(Collectors.toList);流水线的组装,从实现上其实是先从collect这一道TerminlOp工序为起点的?
从代码我们可以得知:确实是这样的,回顾一下ReduceOp的实现:
1 | private abstract static class ReduceOp<T, R, S extends AccumulatingSink<T, R, S>> |
在helper.wrapAndCopyInto(makeSink(), spliterator)中第一次被wrap的Sink就是通过makeSink()方法生成出来的。
综合以上所有,我们发现: Java Stream 中对流水线的组装,从抽象层次角度划分,可以分成三层:
- 业务高层:采用
filter、map、reduce等业务概念描述流水线中的多种工序 - 抽象中层:采用
Head,StatelessOp、StatefulOp、TerminalOp四种形式来完整描述所有的业务工序 - 实现低层:采用
Sink来具体完成实现逻辑,形成各工序的串联

从代码组装的角度划分,可以分成正向/反向两个过程:
正向组装:
从
Head开始,不断在尾部挂载新的工序,包括中间操作或终止操作。反向组装:
从
TerminalOp的makeSink()开始,不断向前包装Sink形成Sink链。

流水线的执行
经过上一节的流水线组装,终于到了要执行流水线的时候了。
详细的看看helper.wrapAndCopyInto(makeSink(), spliterator).get()具体是如何实现的:
1 | // AbstractPipeline.class |
以上AbstractPipeline中的三个方法组成了最终执行流水线的全部动作。
其中,wrapSink()方法接收由ReduceOp的maakeSink()方法所创建出的尾部Sink,之后不断向上查找priviousStaage并调用其opWrapSink()方法,层层包装形成最终的Sink链条,这就是上一节图中所展示的Sink包装具体实现。
wrapSink()最终返回的Sink,包含了所有下游的Sink。
这时该Sink作为参数,与另一个参数splieraator,一起进入
copyInto()方法,通过spliterator.forEachRemaining(wrappedSink)这句话,对Stream中的每一个元素都会从上到下流经一遍所有的
Sink,最终被最后一个Sink(也就是makeSink()方法创建的ReducingSink)所收集,并进行最后的处理。
为了清晰,我们再次放出ReducingSink的实现:
1 | // ReduceOps |
ReducingSink保存了一个共享变量state,其accept()方法调用BinaryOperator.apply(op1, op2)来将到达Sink的
Stream
中前后两个元素进行聚合,最后,由于ReducingSink的父类AccumulatingSink实现了Consumer,因此可以在所有元素都聚合完成后通过get()方法拿到聚合结果。
这整是helper.wrapAndCopyInto(makeSink(), spliterator).get()最后的get()的作用。
结尾
看完了 Java Stream 的实现原理,再想想自从 jdk8
以后在业务代码里随处可见的 Stream
用法,不得不感叹其底层实现的工整、精巧。他以较为复杂的方式实现了流式操作,但最终暴露给用户的,仅仅是Stream.of().filter().map().collect()这样简单、直接的语义,真正做到了设计的高内聚和低耦合。
从代码架构角度看,Stream 的实现采用三层结构,高层引申概念并提供
API,底层抽取共性并实现逻辑,而中层通过业务抽象来衔接高低层。通过这种方式实现了良好的扩展性,有了基础架构,多种多样的功能都能简单的实现出来(这里可以参考distinct、collect等操作符的实现逻辑,无一不实现的清晰而简洁)。
回过头想想我自己日常的 coding,有没有可能尽量通过合理的分层、清晰地设计来更好的表达业务,并提供更强的扩展性呢?这应该是我读完 Stream 的源码后期望能深入思考之处。