虚拟工厂:Java 线程池
工厂
现实生活中,存在大大小小的工厂,他们提供特定的服务,根据用户的需求生产、加工出产品,交付给客户,并赚取服务费。
通常,我们只需要交给工厂一份图纸,工厂就会根据图纸来生产产品,而生产的过程我们是无需关心的,作为客户,我们只关心这间工厂什么时候把产品交付给我们。
类似的,在代码里我们也会存在以下场景:主流程代码将需要做的事情分成一件件任务,并交由对应的代码工厂去执行,这里的任务可以是代码逻辑的执行步骤,而最基本的代码工厂就是各种方法。合并起来,代码工厂执行任务,实际上就是调用方法执行业务逻辑。
不过有时我们期望代码工厂能够异步执行任务,这样主流程就不用一直等待它执行完成了:让互相之间不存在依赖的任务并行执行能大大缩短总体的执行时间。
Java 提供了线程机制允许我们将方法调用放在与主流程独立的线程中执行,不过直接使用线程代码写起来略为繁琐,线程本身也是较低层的概念,所以在 JDK 1.5 之后,提供了对异步任务执行的高层抽象:线程池,通过线程池我们可以更方便的执行异步任务,而不必关心线程的使用细节。
线程池以清晰的设计与简洁的代码优雅的封装了线程并实现了任务执行逻辑。阅读它的代码,就好像走进了一间虚拟的工厂,工人挥舞工具的画面似乎就在眼前。
工厂的代码抽象
试想一间最简陋的工厂至少需要些什么才可以正常运转?
- 工人:干活
- 老板:获得订单,安排生产
老板不断地获取订单任务,将订单任务分发给工人,工人按照订单要求,一个接一个的生产产品,最后交付。
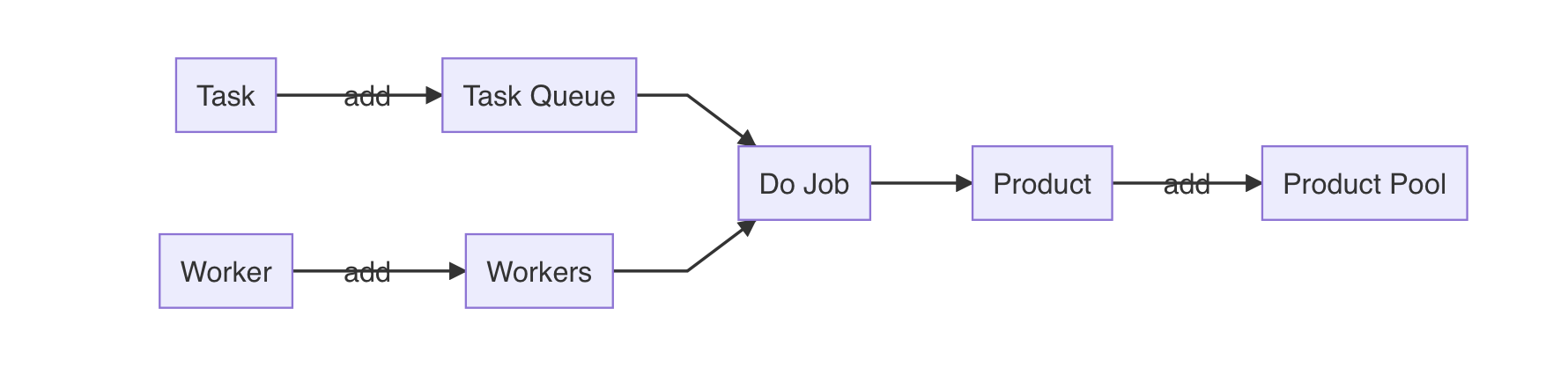
那么,映射到代码里,假如我们想要实现一间代码工厂,我们可能会这样设计:
1 | class Factory { |
整个工厂的运转就是一个大循环,在循环中取出一个待完成的任务,并取出一个空闲的工人,最后将任务执行结果输出到产品池中。其中工人的工作方式
doJob 根据具体业务要求来实现。
上述代码中每一次都必须等待工人执行完任务才能再次循环,这中设计同一时间只有一名工人在工作,这是不合理的,因此稍作改动,将工人干活的部分放到独立的线程中,即可实现高效运转:
1 | ... ... |
Java 任务工厂:线程池
本质上讲,Java 的 ThreadPoolExecutor
其工作原理和前文所述的流程基本一致,ThreadPoolExecutor
本身可类比为工厂,在工厂内定义了以下成员及方法:
1 | public class ThreadPoolExecutor extends AbstractExecutorService { |
可以看到,任务队列由 BlockingQueue<Runnable>
定义,工人集合由 HashSet<Worker>
定义,execute(Runnable) 方法将任务入队,而实际的
runWorker(Worker) 方法,在 whiile 循环内执行
task.run() 来真正的执行任务(实际代码中通过在
Worker 线程内调用 runWorker()
来实现异步执行)。
从以上视角来看,ThreadPoolExecutor
的确与前一节描述的设计大体一致,唯一不同之处在于他并没有提供存放任务执行结果的产品池,实际当中是将任务封装为
FutureTask 以委托其进行结果的存储与关联。
工厂运行细节 -- 初始化工厂
ThreadPoolExecutor 的初始化是一个老生常谈的话题了,包括
corePoolSize和 maximumPoolSize
的关系,任务队列的选取,定制化的 threadFactory 等等。
这些概念都很清晰且容易理解:封装了绝大多数细节,初始化参数不多不少,体现了良好的设计。
简单介绍一下 Executors 类中提供的几种线程池:
FixedThreadPool: 固定的线程数量,最大容量为Integer.MEX_VALUE的LinkedBlockingQueue(可以视为不限制队列容量)SingleThreadPool:FixedThreadPool的特殊情况,只有一个固定线程,可以用做 LoggerCachedThreadPool: 线程数量不设限(最大为Integer.MEX_VALUE),实际工作线程数约等于当前时间窗口的最大吞吐量(工作线程存活期为 60 秒)。使用独特的SynchronousQueue当作任务队列:容量为 0,仅用于解耦客户线程与工作线程。
此外,关于拒绝策略,默认的拒绝策略是直接终止,但有些场景下更保险的做法是通过CallerRunsPolicy来采用类似自适应的策略确保任务不会被丢弃。
最后给出初始化方法:
1 | public ThreadPoolExecutor(int corePoolSize, |
####工厂运行细节 -- 创建工人
在 ThreadPoolExecutor
中,为了对系统资源的优化使用,Worker
不是在初始化后就全部准备好的(毕竟一个 Worker
要独占一个线程),而是随着任务的不断提交来逐步创建出
Worker。同时,在默认情况下,创建出的不超过 corePoolSize 的
Worker 会永远保留,而当任务队列满时会尝试继续创建 Worker,直到达到
maximumPoolSize。这些额外创建出来的 “临时工“
会在一段时间(keepAliveTime)没有任务后自动退出,以节约资源(活多的时候找外包,活少的时候就辞退外包,惨兮兮的外包员工..)。
如上所述,在线程池初始化后是并没有任何的 Worker
,随着任务的来临开始创建 Worker,实际的创建逻辑封装在
addWorker(Runnable firstTask, boolean core)
方法中,如下是创建核心部分:
1 | ... ... |
从框出的语句看到,实际上除了必要的 check
工作与加锁同步以外,实际上就是先创建 Worker,将其加入
workers 集合中,最后将 Worker 内部的线程启动(其实
t.start()这里我觉得在 Worker 中封装一个类似
worker.start() 的方法也许会更清晰)。
从上面的代码中,我们了解到 Worker 包含了自己的线程,那么除此之外,作为一个 Worker,还有什么必须的逻辑呢?来看看 Worker 的代码:
1 | private final class Worker |
通过 Worker 内部类,我们看到 Worker
持有了一个工作线程(同时 Worker 自己也是该线程的
Runable),及其 firstTask,结合前面
addWorker() 中的 t.start()逻辑,我们能知道一个
Worker
会在创建后被启动,并赋以第一个任务,从而开始独立的工作旅程。另外,Worker
自身还是一个 AQS,以确保任务执行期间的同步安全。
了解了 Worker
的内部构造,再次看一遍runWorker()就清晰多了:先执行
fisrtTask,之后在循环中不断地执行从
getTaask()中获取到的任务,getTask()实际上正是从
workQueue 中来获取任务。
至此,看了一圈代码后我们验证了,ThreadPoolExecutor正是按照上一节的流程图来执行任务:
- 创建任务工厂(此时没有 Worker)
- 通过
execute(Runable)接收任务 - 创建 Worker 在独立的线程内执行任务,直到 Worker 数量达到
corePoolSize后新任务入队 - 已创建的 Worker 不断的从任务队列中获取任务来执行,并持续下去
工厂运行细节 -- 生命周期
ThreadPoolExecutor描述了以下几个生命阶段:
- RUNNING: Accept new tasks and process queued tasks
- SHUTDOWN: Don't accept new tasks, but process queued tasks
- STOP: Don't accept new tasks, don't process queued tasks, and interrupt in-progress tasks
- TIDYING: All tasks have terminated, workerCount is zero, the thread transitioning to state TIDYING will run the terminated() hook method
- TERMINATED: terminated() has completed
有趣的是,ThreadPoolExecutor用了一个
AtomicInteger
类型的ctl来同时存储当前运行状态与当前 Worker
数量,采用位存储,以此来简化对两种不同数字的同步更新操作。
结尾
从根本上讲,程序 = 算法 + 数据结构,但似乎我们编写的程序离算法+数据结构越来越远,而离对真实世界的映射越来越近。这也是 OOP 和计算机技术的精髓所在:通过层层抽象与分层,让计算机的指令执行与现实世界的运行逐步统一。
表面上ThreadPoolExecutor是为了减少线程创建和销毁的开销而优化效率,实际上它构造了一间虚拟的工厂,将
”创建一个线程来执行一项异步任务“ 的工作转化为了
”创建一间工厂,将任务委托给工厂生产“,通过一层抽象,隔离了底层线程逻辑,而对效率的提升其实不过是分层后下层更关注性能,而上层更关注业务的结果。
以上这种通过分层隔离关注点,进而按关注点逐个处理的办法,在 JDK 中大量的被使用,例如
ForkJoinPool的引入,使并发执行相互关联的任务(如递归)以提升效率的实现变得非常简单。