理解 K8s 多集群(下):解决方案对比与演进趋势

本文(分上下两部分)介绍了 K8s 多集群的由来以及实现多集群所面临的核心问题,之后分析并探讨了现有的 K8s 多集群方案,最后根据目前实现方案的痛点与挑战,设想了未来的演进趋势。
本篇是下半部分,主要讨论目前实现 K8s 多集群的开源方案、对现状问题的讨论以及可能的演进方向。
1. 几种方案对比
上一篇我们已经讨论了实现多集群管理所涉及到的 4 个核心问题:
- 部署模型:包括了多集群管理控制面所处的位置、集群间网络连通性以及跨集群的服务注册与发现
- 跨集群应用调度:涉及了通用调度模型以及需要通过不同的调度策略对应用和集群的属性进行匹配
- 应用模型扩展:应用模型需要在规格和状态上进行扩展,同时也应考虑前向兼容性以及支持自定义资源
- 集群即资源:为了更灵活的自动扩缩,将集群视为可以进行生命周期管理的资源,并考虑合理的状态模型
接下来我们通过探究常见的一些开源多集群管理方案,来对比它们之间的特性。
1.1 KubeFed
KubeFed 是 Kubernetes 多集群特别兴趣小组(multi-cluster SIG)构建的一套多集群管理方案,是相对较早的试图解决多集群管理问题的开源方案。KubeFed 主要聚焦于通过定义集群联邦来解决跨集群应用模型的定义、应用调度以及服务发现问题。由于多方面的原因,目前 KubeFed 已经归档,不再活跃更新。
KubeFed 的整体架构如下图所示:
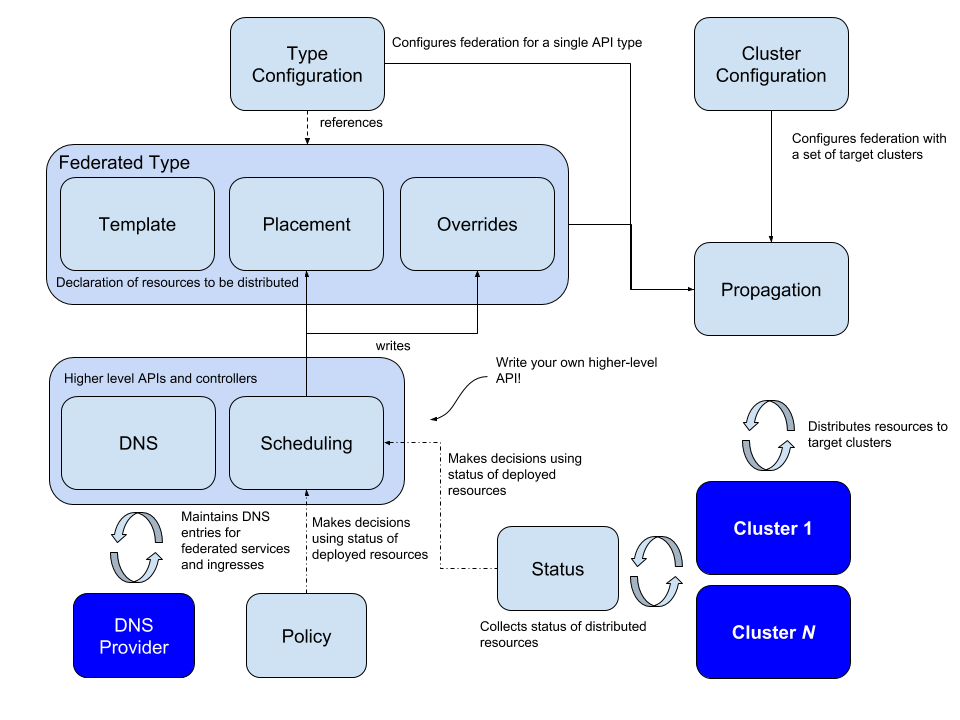
首先,在部署模型上,KubeFed 作为控制面独占一个 K8s 集群,称为 Host
Cluster,而实际部署应用的集群,称为 Member Cluster。任何 K8s
集群,想要成为集群联邦内的一个成员,都需要通过 KubeFed 来进行
“Join”,“Join” 实际上是在 Host Cluster 中创建了一种类型为
KubeFedCluster 的自定义资源(即上图中的 “Cluster
Configuration”),在其中描述了待加入集群的 API 端点,证书、Token
等用于从外部连接到集群的信息,KubeFed 会通过这类信息来向 Member Cluster
下达指令。
应用模型扩展
Member Cluster 加入后,怎么定义跨集群的应用资源呢?在 KubeFed 的概念中,任何可以下发的应用资源类型,都需要被定义为 “联邦资源类型”(FederatedType,如上图),之后才能被 KubeFed 识别并调度。
举例说明,当期望在集群联邦中创建标准的 Deployment 资源时,需要:
1. 创建 CRD,类型起名叫 “FederatedDeployment”,代表新增一种 FederatedType:
一个 FederatedType,在 Spec 定义中必须包含三种元素即:Template,Placement 和 Overrides(如上图),其中 Template 表示 KubeFed 将实际创建的真实资源,在这里便是原生的 Deployment;Placement 代表该 Deployment 将被部署在哪些 Member Cluster 中;而 Overrides 则是用于当某些 Member Cluster 中部署的 Deployment 与其他集群不太一样时,将差异化的部分定义在 Overrides 中。
示例如下:
1 | apiVersion: types.kubefed.io/v1beta1 |
2. 创建了 FederatedType 之后,还需要将其注册至 KubeFed
上述 FederatedDeployment,是由用户定义的 CR,为了使 KubeFed 能真正的监听这个 CR 从而实现应用分发,还需要注册一下。
通过定义一个 “FederatedTypeConfig” 对象实现注册:
1 | apiVersion: core.kubefed.io/v1beta1 |
如此就实现了对 FederatedDeployment 和 Deployment 的关联,KubeFed 在实际创建资源时,会创建 Spec 取自 FederatedDeployment 中 template 的 Deployment 资源。
实际上,标准的 K8s 资源 API 都已经被创建好,在安装 KubeFed 时会一并安装,而如果有自定义资源需要被 Federated,KubeFed 也提供了 kubefedctl CLI 工具来简化操作。
通过上述内容我们会发现,KubeFed 定义的资源模型,是无法前向兼容的,这也就导致如果从单集群迁移到 KubeFed 多集群,需要花费大量成本来适配。
跨集群调度
显然,按上述方式定义的联邦资源,其调度方式属于全静态的预定义资源分发,在 placement 中设定的是什么,KubeFed 就会按照预定值来调度应用。然而这种方式非常不灵活,假如某个 Member Cluster 资源不足,则就会出现调度 Pending。
KubeFed 提供了名为 ReplicaSchedulingPreference
的调度策略来解决动态调度问题:
1 | apiVersion: scheduling.kubefed.io/v1alpha1 |
上述 Spec 中,totalReplicas 代表目标资源的总副本数(10 个),clusters 中通过 weight 来分配不同集群中的副本数(cluster1 分 4 个,cluster2 分 6 个),rebalance 则代表假如某集群资源不足则自动重平衡。基于此,KubeFed 就可以根据集群实际的状态来分配资源,当某个集群中该资源的期望副本数与实际副本数不符时,就可以自动进行动态调度。
当然,这种动态调度只是基于比较简单的规则,并没有对调度策略做过多细化。
服务注册与发现
KubeFed 在最初的设计中通过引入 ”ServiceDNSRecord“ 类型来通过与外部的 DNS 服务交互来实现跨集群的服务发现。
任何需要跨集群发布的服务都应创建 ServiceDNSRecord 类型来告知 KubeFed 可以将对应的服务地址注册到外部的 DNS 服务中,以实现服务的注册和发现。
但是在 KubeFed v2 的 KEP 中提到,KubeFed 将不再使用 ServiceDNSRecord 相关的功能,而是寻求其他方案例如 Service Mesh 等来实现服务注册与发现的功能,因此现在我们会看到,KubeFed 的源码中已经不再包含相关的控制逻辑了。
1.2 Karmada
Karmada 是华为开源的多集群管理系统,目前是 CNCF 的沙箱项目。Karmada 在多集群管理上功能非常丰富,在集群管理、灵活调度、应用模型等方面都提供了较为完善的解决方案。
从部署架构上看(如下图),Karmard 多集群控制面是逻辑上的概念,其控制面进程支持部署在任意 K8s 集群或是 VM 上。控制面组件中,Karmada API Server 用于接受请求,创建的资源存储在 etcd,Karmada Scheduler 用于产生调度决策,而 Karmada 自有的资源,则分别被其对应的 Karmada Controllers 监听并执行实际的动作。可以看到 Karmada 控制面组件的设计与 K8s 非常相似。
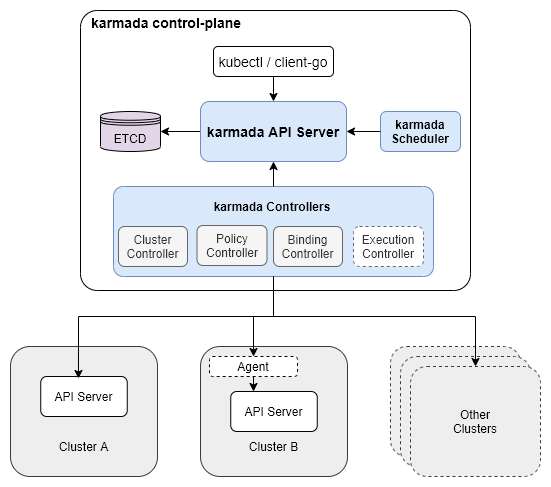
下图是 Karmada 在进行多集群管理过程中引入的一些概念和自有资源,其中:
- Resource Template:指在 Karmada 上下文中的 K8s 资源,如 Deployment,DaemonSet 等等
- PropagationPolicy:资源传播策略,用于定义某个资源模板需要以某些规则下发,可以认为是对调度器的提示
- ResourceBinding:产生调度决策后,会将资源模板与实际下发的集群绑定起来存储在 ResourceBinding 中
- OverridePolicy:对某些特定集群中下发的资源属性进行修改,覆盖模板值
- Work:实际操作资源下发的组件
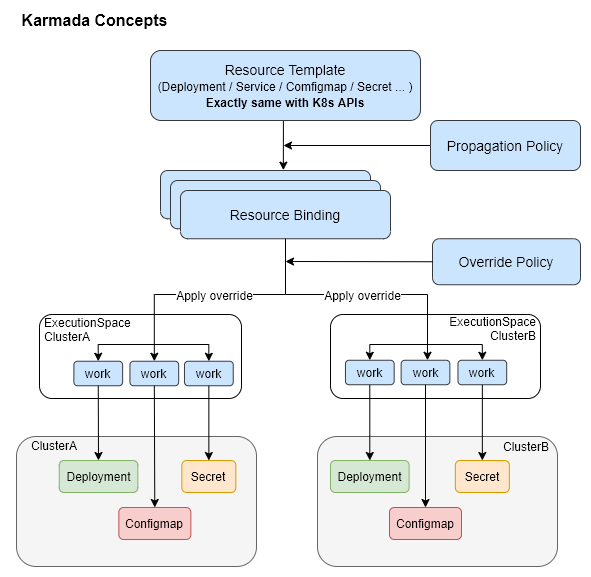
应用模型扩展
Karmada 多集群管理的工作流程是通过用户在 Karmada 上下文(即通过 Karmada API Server)中创建 K8s 资源开始的,用户创建的 K8s 资源在 Karmada 中称为 Resource Template。
如下以一个最简单的 Nginx Deployment 为例:
1 | apiVersion: apps/v1 |
在单集群语境下,上述 Deployment 在创建后 K8s 集群会通过 Kubelet 在某个节点上实际启动 Nginx 容器,而在 Karmada 多集群语境下,该资源会被 Karmada 控制面保存,而不会立即开始尝试启动容器,Karmada 会将该 Deployment 视为一种创建 Nginx 应用的 ”模板“。
之后用户需要再创建一个 PropagationPolicy 资源来描述这个 Nginx 应用实际需要运行的集群:
1 | apiVersion: policy.karmada.io/v1alpha1 |
可见,PropagationPolicy 能通过 resourceSelectors 选中
Nginx Deployment(即选中了资源模板),之后在 placement
段中定义 Nginx 应用的调度策略,clusterAffinity
定义了该应用与 Member 集群的亲和性,在这里指 Nginx 需要在
member1和
member2集群中创建。replicaScheduling
段则描述了资源模板中的 replicas: 6 实际在 Member
集群中的副本数,replicaDivisionPreference 和
replicaSchedulingType 指明六个副本需要按权重平均分配在
Member 集群中,由于 weightPreference 定义了
member1和 member2的权重比例是 1:2,因此在
member1 会部署 2 个副本,而 member2 会部署 4
个副本。
Karmada 的应用资源模型设计是前向兼容的,避免了 KubeFed 中需要修改原始应用资源的问题,从单集群演进而来的应用,最少只需要增加 PropagationPolicy 就能过渡到多集群。
跨集群动态调度
Karmada 的应用跨集群调度实现的很完善,通过多个组件相互配合,不仅实现了传统的由用户指定的亲和性、权重、分组等调度偏好,还支持 Taint/Tolerantion、优先级、基于资源的调度,故障转移,动态重调度等更加自动化的调度方式。
在 Karmada 中与调度相关的组件关系如下图:
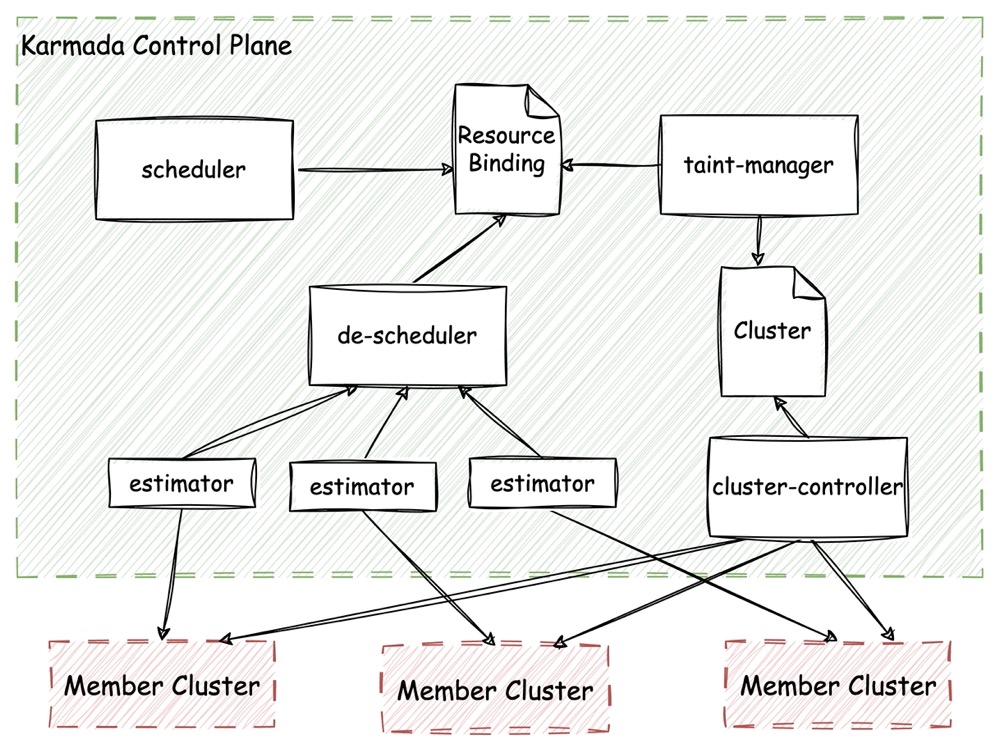
在 Karmada 中,应用期望部署在哪些集群中,副本数有多少,实际状态是什么,都存储在 ResourceBinding 对象中。因此整个调度逻辑也都围绕着 ResourceBinding 来组织。如上图所示,与调度相关的组件包括了调度器 scheduler、重调度器 de-scheduler 以及污点管理器 taint-manager,这些组件产生的调度决策都会作用于 ResourceBinding 上。
灵活的调度模式
在前面示例的 PropagationPolicy 中,已经展示了集群亲和性的配置,除了直接通过 Cluster 名称,还可以采用如 Label/Tag 等方式选择合适的集群。此外,也支持通过 PropagationPolicy 中的 SpreadConstraint 特性来对集群进行分组(例如选择在同一个 Region 内的集群)。调度器 scheduler 通过读取 ResourceBinding 中与 PropagationPolicy 相关的信息来产生调度决策,并将决策结果写回 ResourceBinding。
假如 Member Cluster 出现了故障,集群控制器 cluster-controller 会在对应的 Karmada Cluster 对象上打污点,污点管理器 taint-manager 得知 Member Cluster 上存在污点后,也会修改原调度决策,并将修改作用在 ResourceBinding 上。
动态重调度
重调度器 de-scheduler 通过 estimator 来获取应用在集群中的实际状态,进而决定是否修改原调度决策,这一修改也会落在 ResourceBinding 上。
每个 estimator 都对应一个 Member Cluster,estimator 通过检查应用在当前 Member Cluster 中的目标副本数和实际副本数是否一致来发现调度失败的情况,de-scheduler 汇总所有 estimator 的信息后,就能够知晓某个应用的现状,并决定是否要发起重调度。
网络连通与服务发现
Karmada 支持借助 Submariner 或 Istio 来实现 Member Cluster 之间的网络连通性。通过实现 Multi-Cluster Services API 来支持跨集群的服务注册与发现能力。
网络连通
Submariner 为 K8s 多集群提供了基于 Overlay 网络的连通方案,能够实现跨 L3 层的 Overlay,且不要求多集群使用相同的 CNI 插件。
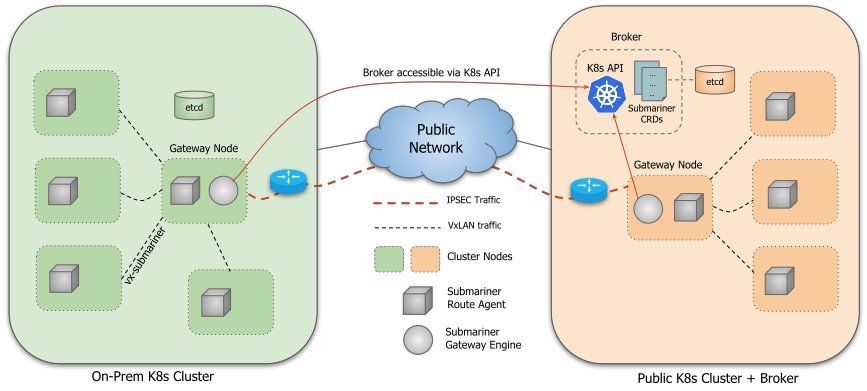
上图是 Submariner 的总体架构,可以看到它本质上是通过 VxLan 技术建立的 Overlay 网络。每个集群内安装 Gateway 来接受跨集群的流量,所有跨集群流量都会通过 Route Agent 路由至 Gateway。Gateway 之间通过公有网络建立基于 IPSec 的加密通道,在其上传输跨集群流量。Broker 可以视为 Submariner 的控制平面,用于控制和协调。
服务发现
Karmada 基于 Multi-Cluster Services API 的 ServiceExport 和 ServiceImport 实现了相关控制逻辑来构建跨集群的服务发现。
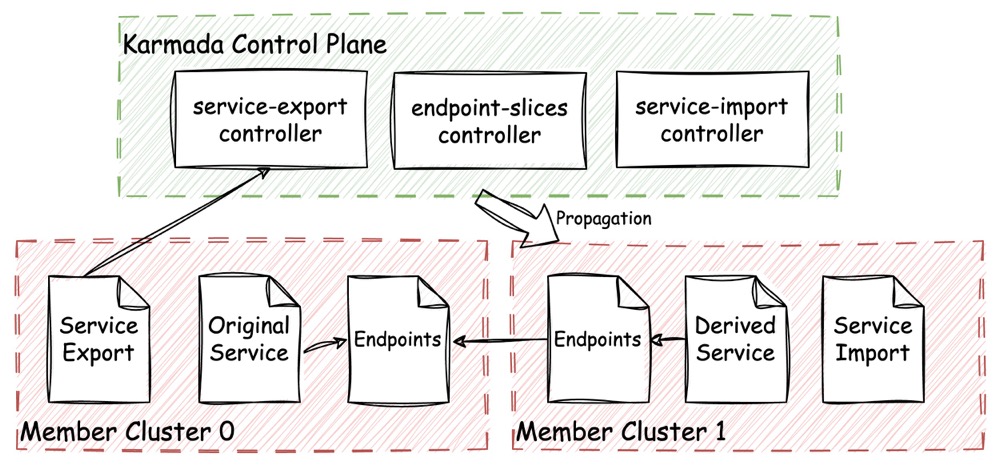
如上图所示,当 Member Cluster 0 中的某个服务 Service 需要被导出时,先由用户创建 ServiceExport。此时 Karmada 的 ServiceExport 控制器会监听到 Member Cluster 0 中创建的 ServiceExport 对象,并配合 EndpointSlice 控制器将 Member Cluster 0 中需要导出的 Service 和对应的 Endpoints 复制一份到 Karmada 控制集群,以备后续导出。
接下来,用户在需要导入服务的集群中(图中是 Member Cluster 1)创建 ServiceImport。一旦 ServiceImport 对象被创建,ServiceImport 控制器就会基于待发布的 Service(Original Service) 创建出对应的 “派生” Service(Derived Service),并和 Endpoints 一并通过 Propagation 机制下发到 Member Cluster 1,实现对 Service 的导入。
1.3 OCM
OCM 即 Open Cluster Management,是阿里与红帽共同推出的一种 K8s 多集群实现方案。其最大的特色在于采用借鉴了 K8s 控制面组件+Kubelet 架构模式的所谓 “Hub-Agent” 设计架构,通过一个小型轻量级的控制集群,就能够管理多至数千个集群。

上图所示的是 OCM 的总体架构,可以发现它与 KubeFed 或 Karmada 最大的区别就在于,其每一个工作集群(OCM 中称为 Managed Cluster)中都安装有一个 “Klusterlet” 组件(恰好类比于 Kubelet)。在多集群管理流程中,控制集群(OCM 中称为 Hub Cluster)只负责生成各个 ManagedCluster 中应当被下发的应用资源模板(OCM 中称为 “处方”),实际的资源管理与状态上报工作,是由 Klusterlet 主动向 Hub Cluster 拉取处方,基于处方的内容管理应用的生命周期,并定期推送应用资源的状态。
正如 OCM 的架构概念所描述的:“试想,如果Kubernetes中没有kubelet,而是由控制平面直接操作容器守护进程,那么对于一个中心化的控制器,管理一个超过5000节点的集群,将会极其困难。 同理,这也是OCM试图突破可扩展性瓶颈的方式,即将“执行”拆分卸入各个单独的代理中,从而让hub cluster可以接受和管理数千个集群。” 比对 Karmada 是通过在控制面创建每个工作集群对应一个的 Work 组件来实施集群管理,OCM 的 Klusterlet 就类似于把 Karmada 的 Work 放在了工作集群上运行。
应用模型扩展
OCM 是通过名为 ManifestWork 的对象来描述应用:
1 | apiVersion: work.open-cluster-management.io/v1 |
一个 ManifestWork 能够描述多个应用资源,此外每一个
Managed Cluster 在 Hub Cluster
中都拥有一个命名空间,ManifestWork
创建在哪个命名空间中,对应 Managed Cluster 的 Klusterlet
就会将其拉取下来,并如实的创建应用资源。而应用资源实际的状态信息,也会由
Klusterlet 更新回 ManifestWork 中。
不过,显然 OCM 的应用模型扩展并没有考虑前向兼容的问题。
动态调度
与 Karmada 很类似,OCM 也是通过名为 Placement
的对象来实现动态调度:
1 | apiVersion: cluster.open-cluster-management.io/v1beta1 |
当Placement 创建过后,调度逻辑会按照其描述来生成名为
PlacementDecision 的调度决策:
1 | apiVersion: cluster.open-cluster-management.io/v1beta1 |
相关控制器监听到调度决策后就会按要求在 Managed Cluster
的命名空间中创建 ManifestWork,完成调度流程。
另外,OCM 的 Add-on 插件体系也提供了灵活的框架来允许用户自定义并扩展内建的调度逻辑。
1.4 Gardener
Gardener 是 SAP 开源的 K8s 多集群解决方案,与前面几种方案不同,Gardener 专注于 K8s 集群即服务(Kubernetes-as-a-Service)。
在设计概念上,Gardener 期望作为一种管理大量 K8s 集群的组件,借助 Gardner,用户能够实现在接入各种不同类型底层基础设施的同时,方便的在其上构建标准的 K8s 集群。
与 Cluster-Api 不同,Gardener 更进一步,除了能在各种差异化基础设施上管理 K8s 集群的生命周期,还能够确保在这些基础设施上运行的 K8s 集群具有完全相同的版本、配置和行为,这能简化应用的多云迁移。Gardener 还提供了一个页面专门介绍其不同版本的标准化K8s 集群与不同云提供商的兼容情况。

上图所示的是 Gardener 的整体架构图。从垂直分层的角度看,Gardener 自身及其管理的 K8s 集群可分为三层:
Garden Cluster:Gardener 的控制集群,主要用于定义并管理实际的 K8s 工作集群。
Seed Cluster:Gardener 并不是直接在基础设施上创建工作集群的,相反,Gardener 定义了 Seed 集群的概念。在 Seed 集群中以标准 K8s Workload 的形式运行着多个工作集群的控制面。这种 ”K8s in K8s“ 的形式简化了工作集群控制面的高可用设计,也非常易于扩展。
Shoot Cluster:工作集群的数据面节点,可以视为实际的工作集群。
在 Garden Cluster 中用户可以通过构建 Seed 对象(Gardener
定义的一种 CR,下同)来描述 Seed 集群,而通过 Shoot
对象来描述 Shoot 集群,最后通过构建 CloudProfile
对象来描述下层基础设施的配置。通常在每一个 IaaS Region 中都会运行一个
Seed Cluster,由它来持有当前 IaaS Region 下工作集群的控制面。每个 Seed
Cluster 中都运行着 Gardenlet 用来从 Garden Cluster
中获取工作集群的创建需求。实际的集群创建动作也是由 Gardenlet
来完成的。
因此 Gardener 的设计类似于将 K8s 的概念扩展到了多集群领域:
- Kubernetes 控制面 = Garden 集群
- Kubelet = Gardenlet
- Node = Seed 集群
- Pod = Shoot 集群
2. 演进趋势
通过上述内容,我们了解到了目前的一些实现 K8s 多集群管理的开源解决方案,它们或多或少的实现了一些我们认为的实现 K8s 多集群的核心要素。
事实上,K8s 多集群的诞生本身就是由于业务发展的需要,因此即使是目前的各种开源方案已经实现了多集群管理的许多能力,但仍然有一些领域支持的并不完善。我们将在这一节讨论 K8s 多集群未来可能需要支持的能力和趋势。
2.1 多租户
提供多租户服务厂商的一项共识就是:“不要信任任何租户”,因为恶意租户是难以避免的。因此讨论多租户时,我们经常会讨论租户间的隔离性和安全性问题。
K8s 本身对多租户的支持一直不太完善,从目前来看大致存在三种多租户实现方案:
基于 Namespace 的隔离
通过 K8s 的 namespace 机制(之后简称 ns),可以把不同的工作负载进行分组和隔离。不同的 ns 之间可以存在同名的工作负载,RBAC 设置权限的粒度也是由 ns 定义的。
因此基于 ns 的逻辑隔离是相对简单的一种多租户形式。只要结合访问控制策略,将租户用户对集群的访问权限限定在某个 ns 下,就能实现最基础的多租。通过设置 ResourceQuota 对象,也可以限制 ns 的资源配额。
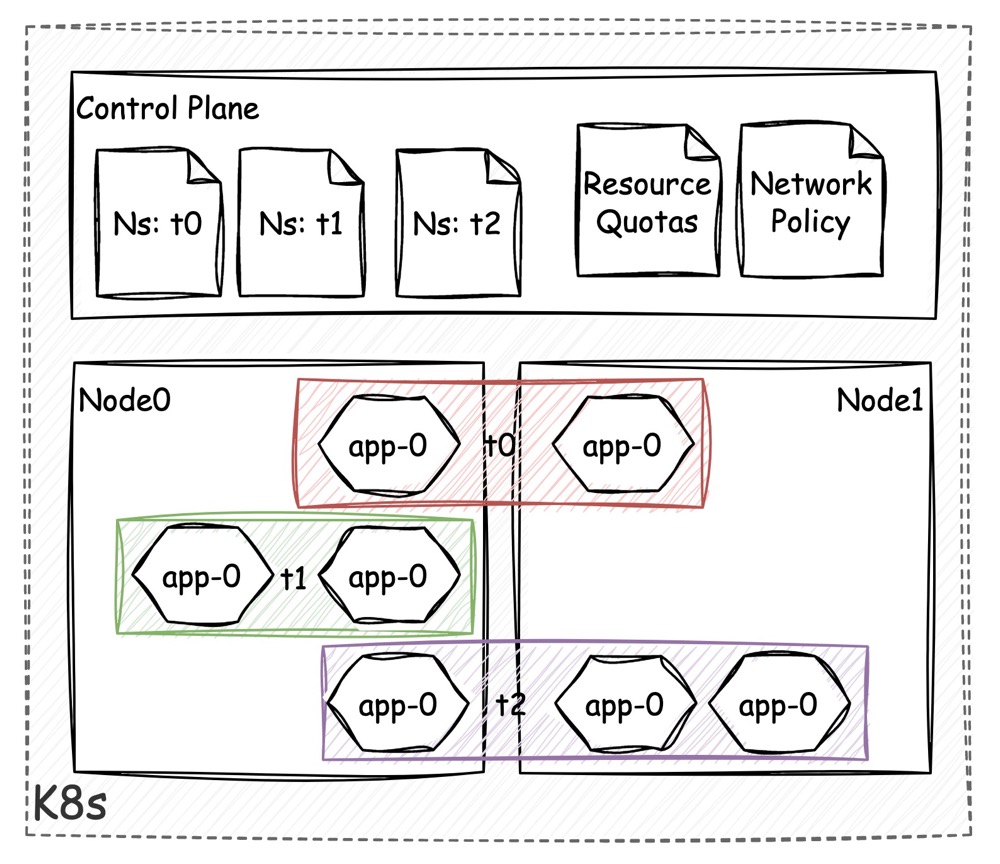
逻辑隔离最大的问题在于这是一种 “在控制面上” 的隔离,即仅在与控制面交互时会受到隔离的限制。某一个 ns 下的租户,可能无法通过 API Server 查看或修改其他 ns 下的工作负载,但实际上由于 K8s 对数据面网络连通性的要求,Pod 之间默认是连通的,因此如果不加以限制,租户之间的应用实际上完全可以相互访问。
通过设置合理的 NetworkPolicy 来控制 Pod 之间的网络流量策略,能够在一定程度上解决上述问题,不过 NetworkPolicy 需要通过 CNI 插件来实现,因此对集群选择的 CNI 插件也提出了一定要求。
另外,数据面隔离还涉及到容器运行时的问题。传统的容器运行时采用的都是共享系统内核的策略,那么就有理由相信恶意容器可能会利用内核漏洞突破容器的限制,访问在同一节点上其他租户的数据。对于这一问题,目前有诸如 Kata Containers、gVisor、Firecracker 等安全容器方案在尝试解决。
基于多集群的隔离
上述逻辑隔离的策略毕竟安全性和隔离性都比较低,在需要更高隔离等级的多租户场景下可能并不适合。
因此本文重点讨论的多集群方案就很容易被用于租户隔离的场景。每个租户拥有自己独立的集群,虽然基础设施可能都处于同一家云提供商,但通过 AZ、VPC 等手段能够方便快捷的实现租户间更高的隔离度(甚至物理隔离)。
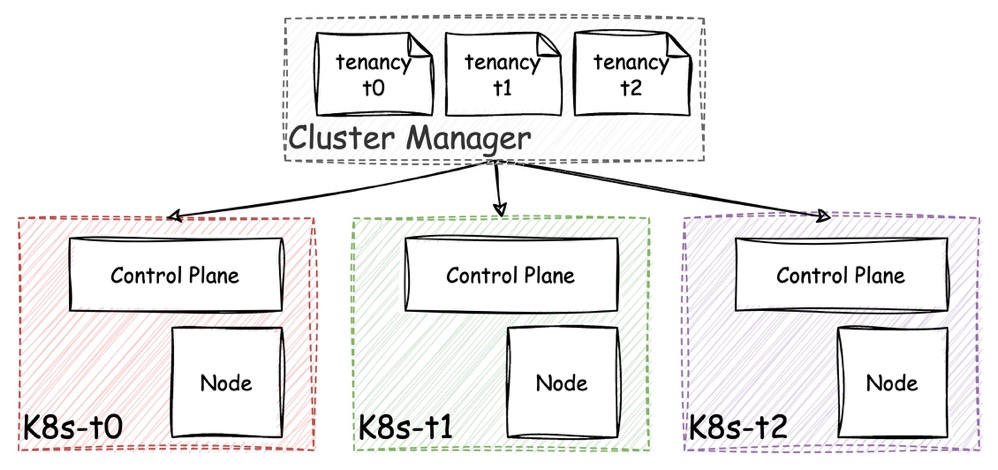
通过 K8s 多集群来实现租户隔离,的确是一种隔离性和安全性都更佳的方案,但 K8s 集群本身的复杂性也导致了小规模集群场景下控制面组件对资源的过多消耗。假如租户应用实际只需要 2 个数据面节点就足够,但为了集群的正常运转,仍旧需要最少 3 个节点来部署控制面组件(以实现最低的组件选举要求)。
K8s 集群控制面资源在总资源中的占比,与数据面节点数量成反比,假如有大量小规模集群租户的存在,要么会导致多租户服务提供商的资源成本过高,要么会导致租户使用服务的起始底价过高,这两点都不利于业务发展。
基于虚拟集群的隔离
K8s multi-tenancy SIG 曾发表过一篇题为 A Multi-Tenant Framework for Cloud Container Services 的论文以阐述他们对现有多租户解决方案中:逻辑隔离安全性不足和集群隔离资源利用率差这两种问题的解法:扩展 K8s 集群,实现租户拥有独立的控制面组件,并共享数据节点。
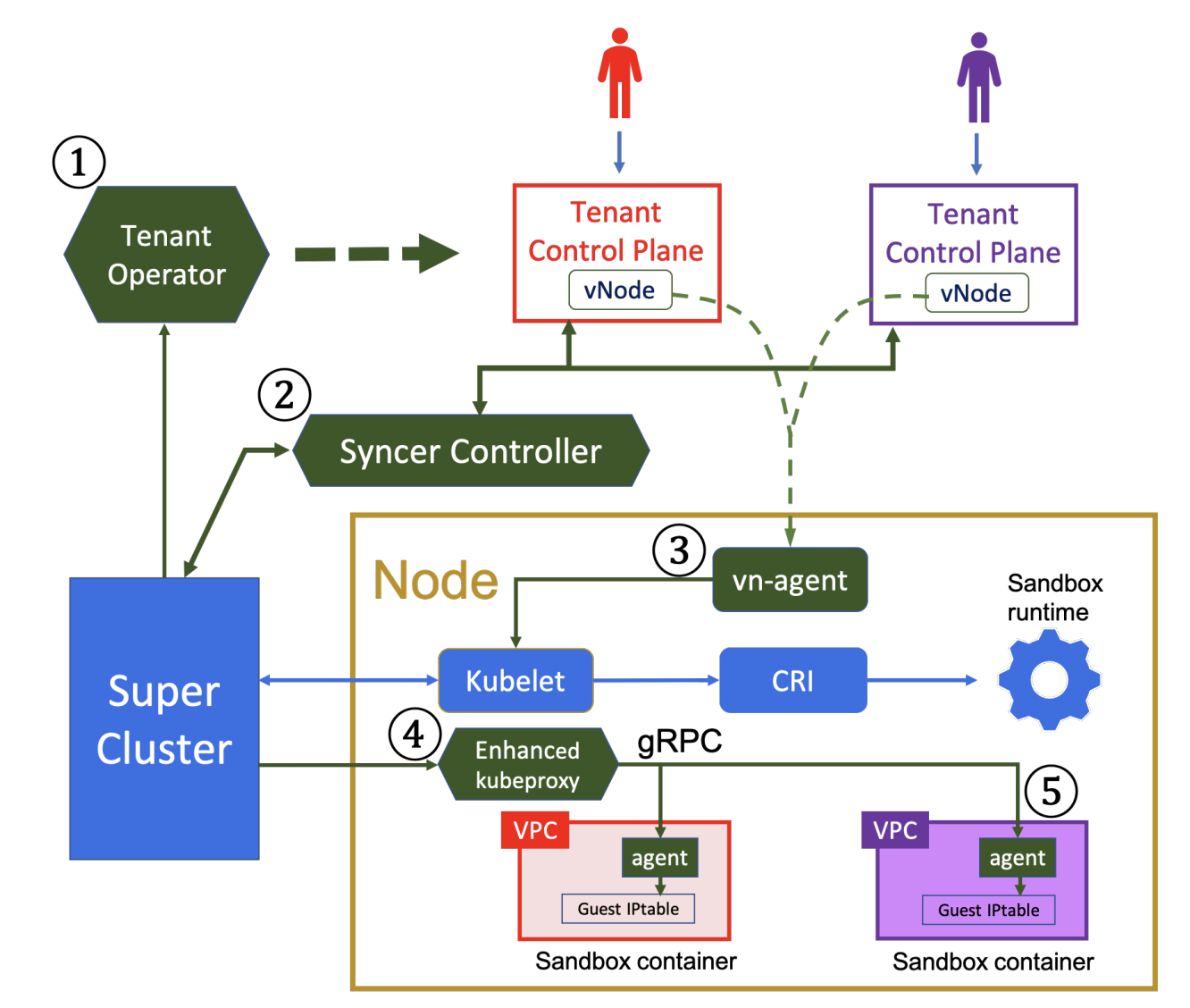
如上图所示,该方案将一个 K8s 集群划分为 “超级集群” 和 “租户集群” 两个概念。租户集群拥有自己独立的控制平面(且不包含调度器,因为实际的调度逻辑由超级集群负责),租户实际创建的 K8s 资源,通过相关组件被代理到超级集群,由超级集群实施管理。共享的节点中,不同租户的 Pod 间基于 VPC 实现网络隔离。而容器本身则采用安全沙箱运行时来避免租户通过特殊手段获取节点 root 权限。
其中,绿色的部分是对原生 K8s 的扩展:
- Tenant Operator:用来维护并管理租户的控制平面,并存储租户控制平面的访问凭据
- Syncer Controller:用来将租户下发的资源请求转发到超级集群,并将超级集群中实际运行的租户资源状态上报给租户集群
- vn-agent:由于租户控制平面不直接拥有
Kubelet,因此租户需要直接对接点进行的一些操作如
log、exec等操作由 vn-agent 来代理 - Enhanced kubeproxy:由于租户 Pod 运行在 VPC 中,为了让超级集群能正常管理 Pod,通过 ⑤ 中的 agent 与 kubeproxy 建立 gRPC 连接,来同步网络信息与路由规则
可以发现虚拟集群的方案有点类似于前文 Gardner 的 “Cluster in Cluster” 的方案,目的也是尽可能的降低多集群的资源消耗,同时实现足够安全的租户隔离。
灵活的多租策略
通过上述几种不同的多租户实现方案,我们能发现目前 K8s 在多租户上存在的一些问题。
通常在实际当中,为了数据安全,基于 K8s 的多租户策略会更倾向于采用多集群的隔离方案。因而上述虚拟集群的方法的确能缓解一部分多集群租户产生的资源浪费。
也许下一代的 K8s 多租户方案,会结合虚拟集群与多集群,实现上层租户需求和底层实际的集群彻底解耦,租户与集群呈现 M:N 的灵活映射关系,这样就能在兼顾资源隔离的同时,提升资源利用率。
2.2 有状态应用的调度
前文跨集群动态调度的内容中,默认被调度应用是无状态且能够任意在集群间迁移的。然而,实际上在很多领域如高性能计算、AI 训练、数据处理等场景下,使用的都是有状态应用。显然,有状态应用不能像无状态应用一样简单的中断并重启,因此需要特别关注有状态应用在迁移过程中的数据备份恢复与一致性。
基于备份恢复资源和卷的迁移
对于有状态应用,我们很容易想到在迁移之前需要备份的 “状态位置“ 可能包括:
- 在 etcd 中存储的资源对象本身
- 应用所绑定的持久卷
因此只要将源集群中的上述内容备份,之后在新集群上恢复就能实现基本的有状态应用迁移了。
Velero 是 VMware 出品的一款开源的云原生迁移工具,其原理就如上文所述,资源对象和卷快照被备份到云存储服务中(如 S3),之后可以将其提取出来恢复到新集群。
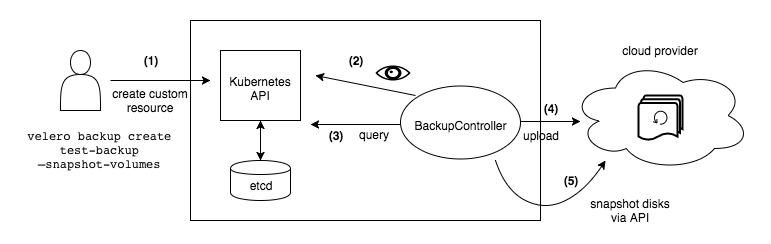
Velero 通过几个基本的 CR 和控制器来管理整个迁移过程:
Backup和BackupController负责备份过程Restore和RestoreController负责恢复过程
类似 Velero 的这种迁移方式,能够很大程度的解决有状态应用的迁移问题。但由于应用的复杂性,这种方式并没能妥善处理应用内存中的状态数据,以及操作系统磁盘缓存中的数据,因此如果不对应用进行特殊改造,就会存在发生迁移后数据丢失的风险。
基于 Checkpoint / Restore 的迁移
CRIU 是 Linux 下的一个用户态软件,它可以获取一个正在运行中的进程的快照,将快照复制到其他的机器上后,又能完全恢复出该进程,并保持打快照时的程序状态。
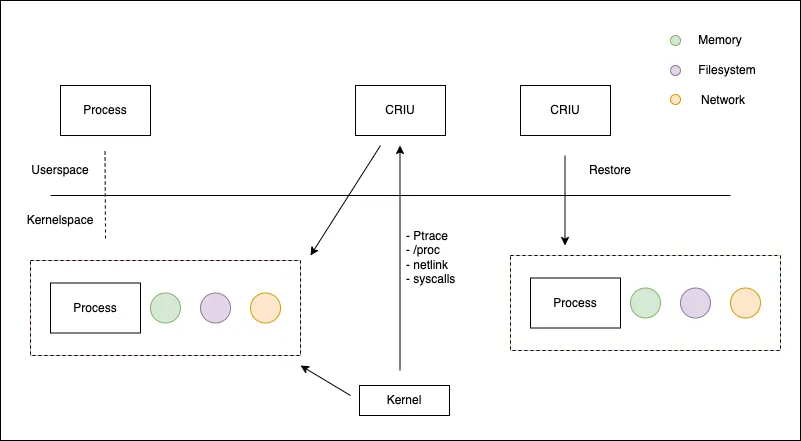
CRIU 所创建的进程快照包含了包括进程内存、文件描述符、进程树、地址空间信息、设备信息等等各种与进程相关数据,因此可以非常完整的恢复整个进程。基于 CRIU 技术可以方便的实现容器的热迁移。
adrianreber 在 K8s 的 sig-node 兴趣小组中提交了一个名为 KEP-2008: Forensic Container Checkpointing 的提案,正是采用了 CRIU 技术来扩展 Kubelet 以实现容器迁移(以及取样分析等),通过调用该 Kubelet API,就可以对任意容器创建一个快照拷贝,并将其用于分析、迁移等用途。该功能目前已经在 K8s v1.25 版本中 alpha。
通过 Checkpoint / Restore 能力,结合前文对资源对象和持久卷的备份/恢复,就可以相对更安全、完整的实现有状态应用的迁移。
有状态应用调度逻辑
基于上述方式我们能够在一定场景下实现有状态应用的迁移过程。
对调度器而言,产生调度决策之前首先需要判断被调度的应用是无状态还是有状态,因此可以通过特殊的标签、annotation 等方式对有状态应用进行标记,以实现对有状态应用的调度。
在产生有状态应用的调度决策后,再通过专有的 Worker 执行调度逻辑,先保存现场,再在新的集群上恢复。
显然,有状态应用的特点决定了迁移过程会显著的慢于无状态应用,因此为了确保用户体验的连续性,调度期间的就绪测试、流量切换等工作非常重要,这些工作都需要相应的逻辑来保障。
3. 总结
本文作为理解 K8s 多集群的下篇文章,基于上篇整理的核心要素,重点介绍了几种开源解决方案的实现原理和架构。并对演进的趋势做了分析和讨论。
从开源方案的实现来看,目前并没有一种包含了所有核心要素的方案,而是围绕不同的侧重点和关注点来进行设计。另外,从演进趋势上看,目前的多集群方案,在多租户隔离以及有状态应用的迁移等方面也存在很多尝试性的方案,并没有形成统一的共识。
上述现状体现了企业在多集群领域的确存在差异化的需求。因此企业在决定采纳多集群技术之前,需要明确当下的痛点和问题,澄清建设多集群的目标,并考量开源方案落地集成和改造的时间和金钱成本。